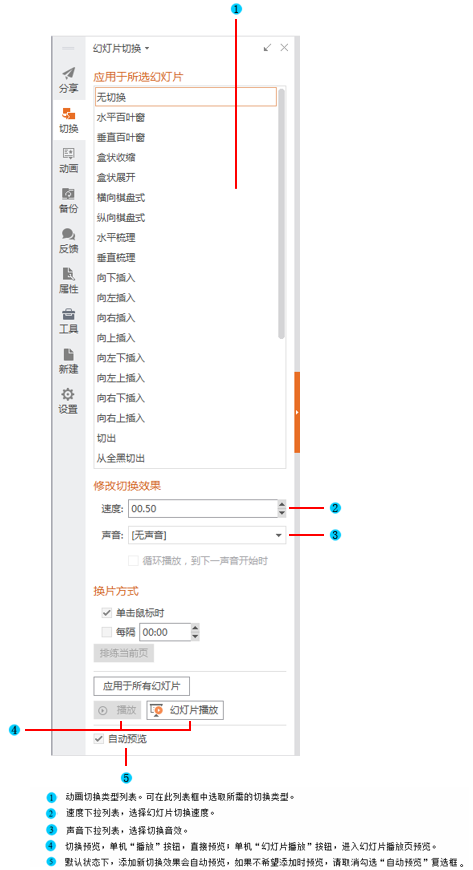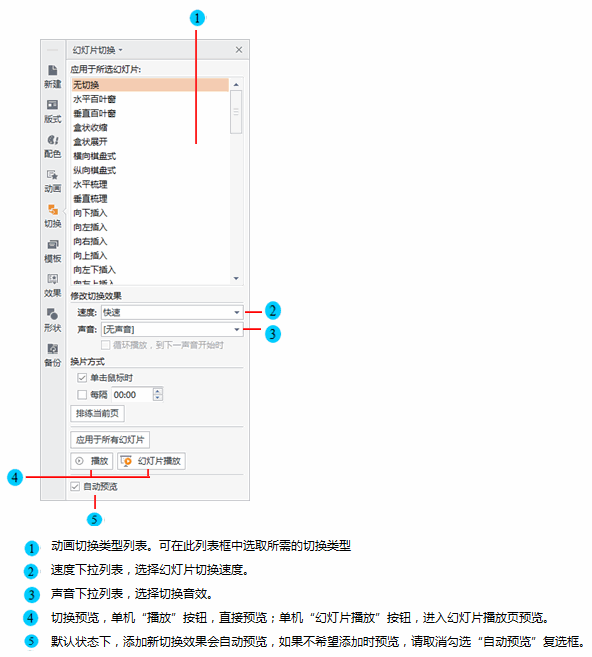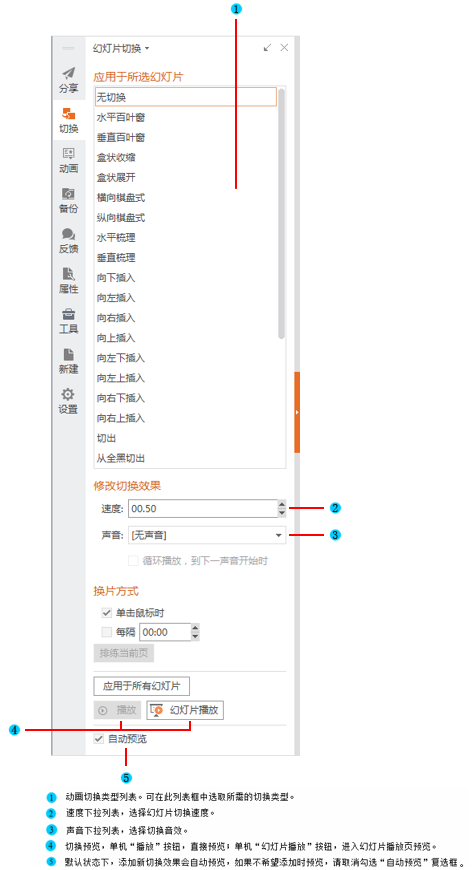
如何让一张幻灯片中的内容一个一个出来(制作幻灯片时,怎样让答案一个一个出来)
1166
2022-05-29

Task的lifetime
Owner负责确保提交的Task的执行,并促进将返回的ObjectRef解析为其基础值。如下图,提交Task的进程被视为结果的Owner,并负责从raylet获取资源以执行Task,Driver拥有A的结果,Worker 1拥有B的结果。

提交Task时,Owner会等待所有依赖项就绪,即作为参数传递给Task的ObjectRefs(请参见Object的lifetime)变得可用。依赖项不需要是本地的;Owner一旦认为依赖项在群集中的任何地方可用,就会立即就绪。当依赖关系就绪时,Owner从分布式调度程序请求资源以执行任务,一旦资源可用,调度程序就会授予请求,并使用分配给owner的worker的地址进行响应。
Owner将task spec通过gRPC发送给租用的worker来调度任务。执行任务后,worker必须存储返回值。如果返回值较小,则工作线程将值直接inline返回给Owner,Owner将其复制到其进程中对象存储区。如果返回值很大,则worker将对象存储在其本地共享内存存储中,并向所有者返回分布式内存中的ref。让owner可以引用对象,不必将对象提取到其本地节点。
当Task以ObjectRef作为其参数提交时,必须在worker开始执行之前解析对象值。如果该值较小,则它将直接从所有者的进程中对象存储复制到任务说明中,在任务说明中,执行worker线程可以引用它。如果该值较大,则必须从分布式内存中提取对象,以便worker在其本地共享内存存储中具有副本。scheduler通过查找对象的位置并从其他节点请求副本来协调此对象传输。
容错:任务可能会以错误结束。Ray区分了两种类型的任务错误:
应用程序级。这是工作进程处于活动状态,但任务以错误结束的任何场景。例如,在Python中抛出IndexError的任务。
系统级。这是工作进程意外死亡的任何场景。例如,隔离故障的进程,或者如果工作程序的本地raylet死亡。
由于应用程序级错误而失败的任务永远不会重试。异常被捕获并存储为任务的返回值。由于系统级错误而失败的任务可以自动重试到指定的尝试次数。
代码参考:
src/ray/core_worker/core_worker.cc
src/ray/common/task/task_spec.h
src/ray/core_worker/transport/direct_task_transport.cc
src/ray/core_worker/transport/依赖关系_解析器.cc
src/ray/core_worker/task_manager.cc
src/ray/protobuf/common.proto
Object的lifetime
下图Ray中的分布式内存管理。worker可以创建和获取对象。owner负责确定对象何时安全释放。
对象的owner就是通过提交创建task或调用ray.put创建初始ObjectRef的worker。owner管理对象的生存期。Ray保证,如果owner是活的,对象最终可能会被解析为其值(或者在worker失败的情况下引发错误)。如果owner已死亡,则获取对象值的尝试永远不会hang,但可能会引发异常,即使对象仍有物理副本。
每个worker存储其拥有的对象的引用计数。有关如何跟踪引用的详细信息,请参阅引用计数。Reference仅在下面两种操作期间计算:
1.将ObjectRef或包含ObjectRef的对象作为参数传递给Task。
2.从Task中返回ObjectRef或包含ObjectRef的对象。
对象可以存储在owner的进程内内存存储中,也可以存储在分布式对象存储中。此决定旨在减少每个对象的内存占用空间和解析时间。
当没有故障时,owner保证,只要对象仍在作用域中(非零引用计数),对象的至少一个副本最终将可用。。
有两种方法可以将ObjectRef解析为其值:
1.在ObjectRef上调用ray.get。
2.将ObjectRef作为参数传递给任务。执行工作程序将解析ObjectRefs,并将任务参数替换为解析的值。
当对象较小时,可以通过直接从owner的进程内存储中检索它来解析。大对象存储在分布式对象存储中,必须使用分布式协议解析。
当没有故障时,解析将保证最终成功(但可能会引发应用程序级异常,例如worker segfault)。如果存在故障,解析可能会引发系统级异常,但永远不会挂起。如果对象存储在分布式内存中,并且对象的所有副本都因raylet故障而丢失,则该对象可能会失败。Ray还提供了一个选项,可以通过重建自动恢复此类丢失的对象。如果对象的所有者进程死亡,对象也可能失败。
代码参考:
src/ray/core_worker/store_Provider/memory_store/memory_store.cc
src/ray/core_worker/store_Provider/plasma_store_provider.cc
src/ray/core_worker/reference_count.cc
src/ray/object_manager/object_manager.cc
Actor的lifetime
Actor的lifetimes和metadata (如IP和端口)是由GCS service管理的.每一个Actor的Client都会在本地缓存metadata,使用metadata通过gRPC将task发送给Actor.
如上图,与Task提交不同,Task提交完全分散并由Task Owner管理,Actor lifetime由GCS服务集中管理。
在Python中创建Actor时,worker首先同步向GCS注册Actor。这确保了在创建Actor之前,如果创建worker失败的情况下的正确性。一旦GCS响应,Actor创建过程的其余部分将是异步的。Worker进程在创建一个称为Actor创建Task的特殊Task队列。这与普通的非Actor任务类似,只是其指定的资源是在actor进程的生存期内获取的。创建者异步解析actor创建task的依赖关系,然后将其发送到要调度的GCS服务。同时,创建actor的Python调用立即返回一个“actor句柄”,即使actor创建任务尚未调度,也可以使用该句柄。
Actor的任务执行与普通Task 类似:它们返回futures,通过gRPC直接提交给actor进程,在解析所有ObjectRef依赖关系之前,不会运行。和普通Task主要有两个区别:
执行Actor任务不需要从调度器获取资源。这是因为在计划其创建任务时,参与者已在其生命周期内获得资源。
对于Actor的每个调用者,任务的执行顺序与提交顺序相同。
当Actor的创建者退出时,或者群集中的作用域中没有更多挂起的任务或句柄时,将被清理。不过对于detached Actor来说不是这样的,因为detached actor被设计为可以通过名称引用的长Actor,必须使用ray.kill(no_restart=True)显式清理。
Ray还支持async actor,这些Actor可以使用asyncio event loop并发运行任务。从调用者的角度来看,向这些actor提交任务与向常规actor提交任务相同。唯一的区别是,当task在actor上运行时,它将发布到在后台线程或线程池中运行的异步事件循环中,而不是直接在主线程上运行。
代码参考:
src/ray/core_worker/core_worker.cc
src/ray/core_worker/transport/direct_actor_transport.cc
src/ray/gcs/gcs_server/gcs_actor_manager.cc
src/ray/gcs/gcs_server/gcs_actor_scheduler.cc
src/ray/protobuf/core_worker.proto
故障模型
Ray工作节点设计的是完全同构,因此任何单个节点都可能丢失,而不会导致整个群集崩溃。当前的例外是头节点,因为它承载的GCS目前未做高可用。
所有节点都被分配一个唯一的标识符,并通过心跳相互通信。GCS负责群集的成员管理,如哪些节点当前处于活动状态。GCS会对任何超时的节点ID进行处理,在该节点上使用不同的节点ID启动新的raylet,以便重用物理资源。如果一个alive的raylet超时,会立刻退出。节点的故障检测当前不处理网络分区:如果工作节点与GCS所在分区隔离了,它就会超时并标记为已死。
每个raylet向GCS报告所有本地worker的death事件。GCS广播这些失败事件,并使用它们来处理Actor death。所有worker进程都与其节点上的raylet fate-share。
raylet负责防止单个工作进程故障后群集资源和系统状态的泄漏。对于失败的工作进程(本地或远程),每个raylet负责:
释放任务执行所需的集群资源,如CPU。这是通过kill 失败的worker 进程。Fail 的worker 提出的任何未完成的资源请求也将被取消。
释放用于该worker 拥有的对象的任何分布式对象存储内存(请参见内存管理)。同时也会清理对象目录中的关联entries。
系统故障模型意味着Ray中的任务和对象将与其owner共享命运。例如,如果运行a的worker在此场景中失败,则将收集在其子树中创建的任何对象和任务(灰色的b和z)。如果b是在a’的子树中创建的actor,情况也是如此。主要影响是:
如果试图获取此类对象的值,任何其他实时进程都将收到应用程序级异常。例如,如果在上述场景中z ObjectRef已传递回driver,则driver将在ray.get(z)上收到错误。
通过修改程序将不同的任务放置在不同的子树(即通过嵌套函数调用),可以将故障隔离。
应用程序将与driver共享命运,driver是所有ownership tree的根。
避免fate-shareing行为的选项是使用detached actor,该actor可能会超过其原始driver的生存期,并且只能通过程序的显式调用销毁。detached actor本身可以拥有任何其他任务和对象,一旦被摧毁,这些任务和对象将与actor分享命运。
后续会支持对象溢出,这将允许对象在其所有者的生命周期内持续存在。
Ray提供了一些选项来帮助透明恢复,包括自动任务重试、参与者重新启动和对象重建。
Object 管理
进程内存储 VS 分布式对象存储,上图描述了提交依赖于对象(x)的任务(a)时分配内存的方式的差异。
在Ray中小对象存储在其所有者的进程内存储中,而大对象存储在分布式对象存储中。这个设计主要是为了减少每个对象的内存占用空间和解析时间。在后一种情况下,进程中存储中会保存一个占位符,以指示该对象已提升到共享内存。
进程内存储中的对象可以通过直接内存副本快速解析,但由于额外的副本,许多进程引用时可能会占用更高的内存。单个worker中存储的容量也仅限于该计算机的内存容量,限制了在任何给定时间可以引用的此类对象的总数。对于多次引用的对象,吞吐量也可能受到所有者进程的处理能力的限制。
分布式对象存储中的对象的解析需要至少一个IPC从worker到worker的本地共享内存存储。如果worker的本地共享内存存储尚未包含对象的副本,则可能需要额外的RPC。另一方面,由于共享内存存储是用共享内存实现的,因此同一节点上的多个工作进程可以引用对象的同一副本。如果对象可以用零副本反序列化,这可以减少总体内存占用。使用分布式内存还允许进程引用对象,而不使对象本地,这意味着进程可以引用总大小超过单个计算机内存容量的对象。最后,吞吐量可以随着分布式对象存储中的节点数量而扩展,因为对象的多个副本可能存储在不同的节点上。
参考代码:
src/ray/core_worker/store_provider/memory_store/memory_store.cc
src/ray/core_worker/store_provider/plasma_store_provider.cc
src/ray/common/buffer.h
src/ray/protobuf/object_manager.proto
Object 解析
对象的值可以使用ObjectRef解析,ObjectRef包括两个字段:
唯一的20字节标识符。这是生成对象的任务ID和该任务迄今创建的整数对象的级联。
对象所有者(worker)的地址。这包括工作进程的唯一ID、IP地址和端口以及本地Raylet的唯一ID。
小对象可以通过直接从所有者的进程内存储中复制来解析。例如,如果所有者调用ray.get,系统将从本地进程内存储查找并反序列化值。如果所有者提交了从属任务,它将通过将值直接复制到任务描述中来内联对象。请注意,这些对象是所有者进程的本地对象:如果借用者尝试解析值,则对象将升级到共享内存,在共享内存中,可以通过下面描述的分布式对象解析协议检索它。
上图为大对象解析,对象x最初是在节点2上创建的(例如,返回值的任务在该节点上运行),所有者(任务的调用者)调用ray.get时的步骤:
查找对象在GCS中的位置。
选择位置并发送对象副本的请求。
接收对象。
大对象存储在分布式对象存储中,必须使用分布式协议解析,如果对象已存储在引用持有者的本地共享内存存储中,则引用持有者可以通过IPC检索对象。这将返回一个指向共享内存的指针,该指针可能会被同一节点上的其他工作线程同时引用。
如果对象在本地共享内存存储中不可用,则引用持有者通知其本地raylet,然后后者尝试从远程raylet获取副本。raylet从对象目录中查找位置并请求其中一个raylet传输对象。
参考代码:
src/ray/common/id.h
src/ray/object_manager/object_directory.h
内存管理
远程任务的对象值由执行的worker计算。如果值较小,工作线程将直接将值回复给owner,该值将复制到owner的进程中存储;如果该值较大,则执行工作程序将该值存储在其本地共享内存存储中,共享内存对象的此初始副本称为主副本。
如上图:主副本vs可驱逐副本。主副本(节点2)不能被删除, 但是,节点1(通过ray.get创建)和节点3(通过任务提交创建)上的副本可以在内存压力下被删除。
主副本是唯一的,因为只要对象的所有者引用计数大于0,它就不会被删除,这与对象的其他副本形成了鲜明对比,后者可能会在本地内存压力下被LRU淘汰删除。因此,如果单个对象存储包含所有主副本,占用内存容量,另一个对象试图存储的时候应用程序可能会收到OutOfMemoryError。
在大多数情况下,主副本是要创建对象的第一个副本。如果初始副本因故障而丢失,owner将尝试根据对象的可用位置指定新的主副本。
一旦对象引用计数变为0,对象的所有副本最终将自动垃圾收集。owner将立即从进程中存储中删除小对象,大对象由Raylet异步从分布式对象存储中擦除。
Raylet还管理分布式对象传输,该传输根据对象当前需要的位置创建对象的额外副本,例如,如果依赖于对象的任务被调度到远程节点。
引用计数
每个工作进程存储其拥有的每个对象的引用计数, owner的本地引用计数包括本地Python引用计数和owner提交的依赖于对象的挂起任务数, 当Python ObjectRef被释放时,前者将递减, 当依赖于对象的任务成功完成时,后者将递减(请注意,以应用程序级异常结束的任务算作成功)。
ObjectRefs也可以通过将它们存储在另一个对象中来复制到另一个进程, 接收ObjectRef副本的进程称为借用者。例如:
@ray.remote def temp_borrow(obj_refs): # Can use obj_refs temporarily as if I am the owner. x = ray.get(obj_refs[0]) @ray.remote class Borrower: def borrow(self, obj_refs): self.x = obj_refs[0] x_ref = foo.remote() temp_borrow.remote([x_ref]) # Passing x_ref in a list will allow `borrow` to run before the value is ready. b = Borrower.remote() b.borrow.remote([x_ref]) # x_ref can also be borrowed permanently by an actor
如果worker仍在借用任何引用,owner将worker的ID添加到本地borrowers列表中。borrower保留第二个本地引用计数,类似于owner,一旦borrower的本地引用计数变为0,owner要求borrower响应。此时,owner可以从borrower列表中删除工人并收集对象。在上面的示例中,Borrower actor正在永久借用引用,因此在 Borrower actor本身超出范围或死亡之前,owner不会释放对象。
borrower也可以递归地添加到owner列表中。如果borrower本身将ObjectRef传递给另一个进程,则会发生这种情况。在这种情况下,当borrower响应owner其本地引用计数为0时,它还包括它创建的任何borrower,owner反过来使用相同的协议联系这些新borrower。
类似的协议用于跟踪其owner返回的ObjectRef。例如:
@ray.remote def parent(): y_ref = child.remote() x_ref = ray.get(y_ref) x = ray.get(x_ref) @ray.remote def child(): x_ref = foo.remote() return x_ref
当child函数返回时,x_ref的owner(执行child的worker)将标记x_ref包含在y_ref中。然后,owner将parrentworker添加到x_ref的borrower列表中。从这里开始,协议与上面类似:owner向parentworker发送一条消息,要求borrower在其对y_ref和x_ref的引用超出范围后回复。
不同类型的引用及其更新方式的摘要:
在远程函数或类定义中捕获的引用将被永久固定。例如:
x_ref = foo.remote() @ray.remote def capture(): ray.get(x_ref) # x_ref is captured. It will be pinned as long as the driver lives.
也可以通过使用ray.cloudPickle拾取ObjectRef来创建“带外”引用。在这种情况下,将向对象的计数添加永久引用,以防止对象超出范围。其他带外序列化方法(例如,传递唯一标识ObjectRef的二进制字符串)不能保证有效,因为它们不包含所有者的地址,而且所有者不会跟踪引用。
代码参考:
src/ray/core_worker/reference_count.cc
python/ray/includes/object_ref.pxi
java/runtime/src/main/java/io/ray/runtime/object/ObjectRefImpl.java
上述相同的引用计数协议用于跟踪(non-detached)actor的生存期。虚拟对象用于表示actor。此对象的ID是根据参与者创建任务的ID计算的。actor的创建者拥有虚拟对象。
当Python actor句柄被释放时,这将减少虚拟对象的本地引用计数。当在actor句柄上提交任务时,这将增加虚拟对象的已提交任务计数。当actor句柄传递给另一个进程时,接收进程将被计算为虚拟对象的借用者。一旦引用计数达到0,所有者就会通知GCS服务销毁参与者是安全的。
代码参考:
src/ray/core_worker/Actor_handler.cc
python/ray/Actor.py
java/api/src/main/java/io/ray/api/ActorCall.java
当对象是Python中引用循环的一部分时,Python垃圾收集器不保证这些对象将及时被垃圾收集。由于未收集的Python ObjectRefs可以虚假地在分布式对象存储中保持Ray对象的活动状态,因此当对象存储接近容量时,Ray会定期在所有Python工作线程中触发gc.collect(),这确保了Python引用循环永远不会导致虚假的对象存储满的状态。
Object 丢失
小对象:存储在进程中对象存储中的小对象与其onwer共享命运。由于借用的对象被提升到共享内存,因此任何借用者都将通过下面描述的分布式协议检测故障。
如果对象从分布式内存中丢失:对象的非主副本可能会丢失,而不会产生任何后果。如果对象的主副本丢失,所有者将尝试通过查找对象目录中的剩余位置来指定新的主副本。如果不存在,则owner存储在对象解析期间将引发的系统级错误。
Ray支持对象重建,或通过重新执行创建对象的任务恢复丢失的对象。启用此功能时,所有者缓存对象:在内存中重新创建对象所需任务的描述。然后,如果所有对象副本都因失败而丢失,所有者将重新提交返回对象的任务。任务所依赖的任何对象都会递归重建。
使用ray.put创建的对象不支持对象重建:这些对象的主副本始终是所有者的本地共享内存存储。因此,如果主副本不能独立于所有者进程丢失。
如果存储在分布式内存中的对象的所有者丢失:在对象解析期间,raylet将尝试查找对象的副本。同时,raylet将定期联系所有者,检查所有者是否还活着。如果所有者已死亡,raylet将存储一个系统级错误,该错误将在对象解析期间引发到引用持有者。
对象溢出和持久化
一旦对象存储已满,Ray 1.3+将对象溢出到外部存储, 默认情况下,对象会溢出到本地文件系统。
任务调度 分布式
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。