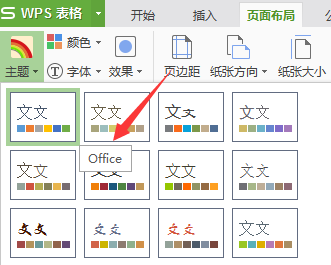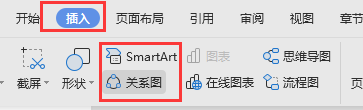
如何生成构架图(结构图生成)
813
2022-05-29

数据集位于lda安装目录的tests文件夹中,包含三个文件:reuters.ldac, reuters.titles, reuters.tokens。
reuters.titles包含了395个文档的标题
reuters.tokens包含了这395个文档中出现的所有单词,总共是4258个
reuters.ldac有395行,第i行代表第i个文档中各个词汇出现的频率。以第0行为例,第0行代表的是第0个文档,从reuters.titles中可查到该文档的标题为“UK: Prince Charles spearheads British royal revolution. LONDON 1996-08-20”。
# !/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl import lda import lda.datasets from pprint import pprint if __name__ == "__main__": # document-term matrix X = lda.datasets.load_reuters() print(("type(X): {}".format(type(X)))) print(("shape: {}\n".format(X.shape))) print((X[:10, :10])) # the vocab vocab = lda.datasets.load_reuters_vocab() print(("type(vocab): {}".format(type(vocab)))) print(("len(vocab): {}\n".format(len(vocab)))) print((voca

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。