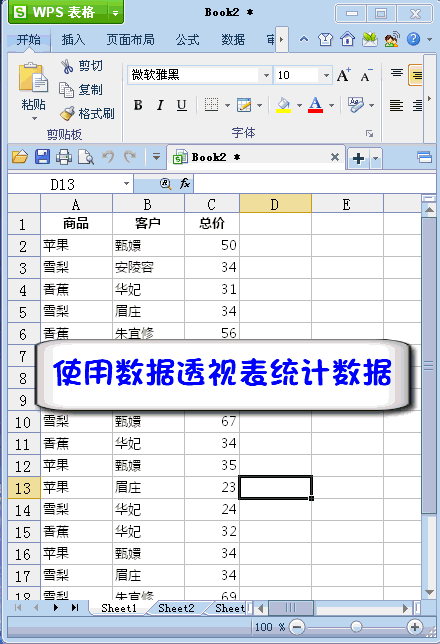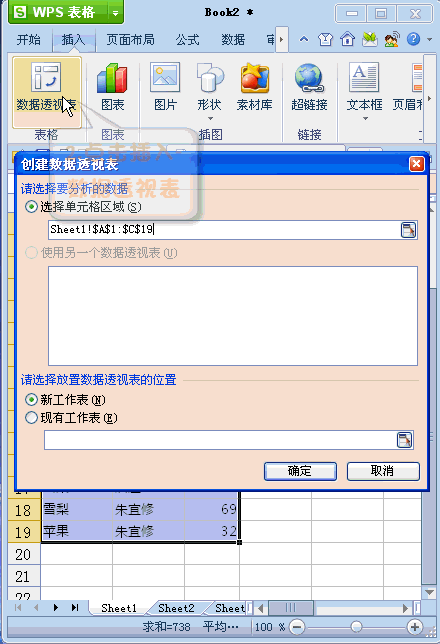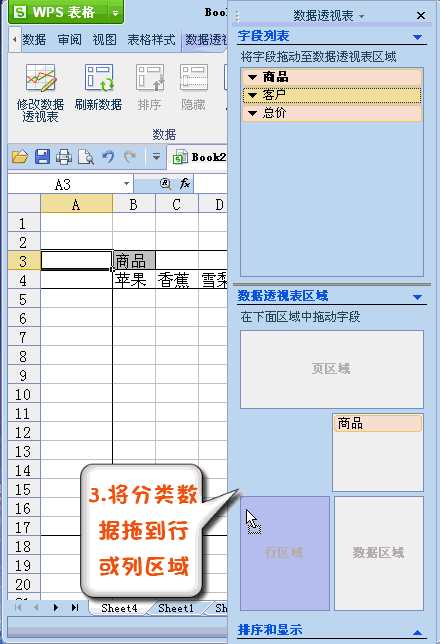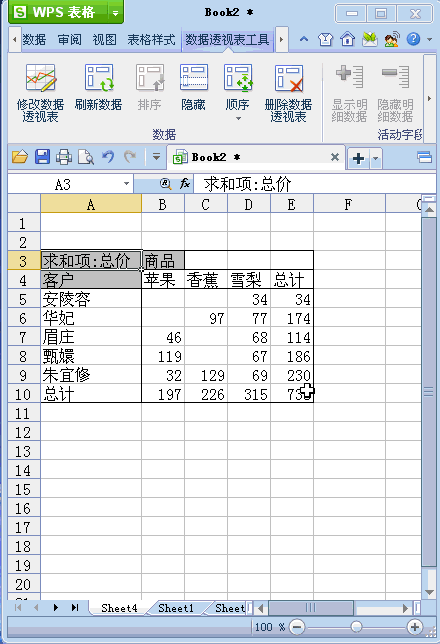
数据透视怎么弄(数据透视怎么做)
718
2022-05-29

MongoDB
创建数据库
- 格式:use DATABASE_NAME - use ruochen - db
创建数据库需要插入一条数据才会在列表中显示
- db.ruochen.insert({‘name’: ‘若尘’})
- show dbs
删除数据库
格式:db.dropDatabase()
use ruochen
db.dropDatabase()
show dbs
创建集合
- 格式:db.createCollection(name, options) - name: 要创建的集合名称 - options: 可选参数,指定有关内存大小及索引的选项
在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段
实例 # 在test数据库中创建ruochen 集合 use test db.createCollection('ruochen') # 查看已有集合 show collections db.createCollection('test', {capped: true, autoIndexId: true, size: 1024000, max: 10000}) # autoIndexId 已弃用,默认_id添加索引 # 插入文档时,MongoDB会自动创建集合 db.ruochen.insert({'name': 'ruochen'})
删除集合
格式:db.collection.drop()
use ruochen
db.createCollection(‘ruochen’) # 创建集合
show tables
db.ruochen.drop()
show tables
插入文档
格式:db.COLLECTION_NAME.insert(document)
方法1
db.ruochen.insert({title: ‘MongoDB 教程’,
description: ‘shu ju ku’,
by: ‘ruochen’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’]
})
db.ruochen.find()
方法2
document=({title: ‘mongodb’,
description: ‘shu ju ku’,
by: ‘ruochen’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’]
})
db.ruochen.insert(document)
db.ruochen.find()
db.collection.insertOne() # 向指定集合中插入一条文档数据
db.collection.insertMany() # 向指定集合中插入多条文档数据
var document = db.ruochen.insertOne({“e”: 3})
document
var res = db.ruochen.insertMany([{‘a’: 1}, {‘b’: 2}])
res
一次插入多条数据
先创建数组
将数据放在数据中
一次insert到集合中
案例
var arr = [];
for(var i = 1; i < 5; i++){
arr.push({num:i});}
db.num.insert(arr);
更新文档
格式 db.collection.update(
删除文档
语法: db.collection.remove(
查询文档
语法: db.collection.find(query, projection) 参数说明 query: 可选,使用查询操作符指定查询条件 projection: 可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略) # 以易读的方式读取数据 db.ruochen.find().pretty()
AND条件
find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件
格式:
db.ruochen.find({key1: value1, key2: value2}).pretty()
案例
db.ruochen.find({‘by’: ‘ruochen’, ‘likes’: 200}).pretty()
类似于 where by=‘ruochen’ and likes=200
or条件
格式
db.ruochen.find( { $or:[ {key1: value1}, {key2: value2} ] } ).pretty()
案例
db.ruochen.find({$or:[{‘likes’: 2}, {‘likes’:200}]}).pretty()
AND和OR联合
db.ruochen.find({‘likes’: {$gt:100}, $or: [{‘likes’: 2}, {‘likes’: 200}]}).pretty()
条件操作符
db.ruochen.insert({ title: 'python', description: 'i love python', by: 'ruochen', url: 'xxx', tags: ['python'], likes: 200 }) db.ruochen.insert({ title: 'php', description: 'php是世界上最好的语言', by: 'ruochen', url: 'xxx', tags: ['php'], likes: 150 }) db.ruochen.insert({ title: 'MondoDB', description: 'NoSQL数据库', by: 'ruochen', url: 'xxx', tags: ['mongodb'], likes: 100 }) # 获取 'ruochen' 集合中 'likes' 大于100的数据 db.ruochen.find({likes: {$gt: 100}}).pretty() # 类似于SQL语句 Select * from ruochen where likes > 100; 获取 'ruochen' 集合中 'likes' 大于等于100的数据 db.ruochen.find({likes: {$gte: 100}}).pretty() # 类似于SQL语句 Select * from ruochen where likes >= 100; # 获取 'ruochen' 集合中 'likes' 小于150的数据 db.ruochen.find({likes: {$lt: 150}}).pretty() # 类似于SQL语句 Select * from ruochen where likes < 150; # 获取 'ruochen' 集合中 'likes' 小于等于150的数据 db.ruochen.find({likes: {$lte: 150}}).pretty() # 类似于SQL语句 Select * from ruochen where likes <= 150;
MongoDB 使用 (<) 和 (>) 查询 - $lt 和 $gt
获取"ruochen"集合中 “likes” 大于100,小于 200 的数据
db.ruochen.find({likes: {$lt: 200, $gt: 100}}).pretty()
类似SQL语句
Select * from ruochen where likes > 100 and likes < 200;
模糊查询
查询title中包含 ‘py’ 的文档
db.ruochen.find({title:/py/}).pretty()
查询title字段以 ‘p’ 开头的文档
db.ruochen.find({title:/^p/}).pretty()
查询title 字段以 ‘p’ 结尾的文档
db.ruochen.find({title:/p$/}).pretty()
MongoDB $type 操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果
获取 “ruochen” 集合中 title 为 String 的数据
db.ruochen.find({‘title’: {$type: 2}}).pretty()
db.ruochen.find({‘title’: {$type: String}}).pretty()
Limit与Skip方法
Limit() 方法
在MongoDB中读取指定数量的数据记录, 使用MongoDB的Limit方法
limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数
语法
db.COLLECTION_NAME.find().limit(NUMBER)
案例
db.ruochen.find().limit(2)
Skip() 方法
skip()方法跳过指定数量的数据
skip方法接受一个数字参数作为跳过的记录条数
语法
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
案例
db.ruochen.find().limit(1).skip(1)
skip() 方法默认参数为0
MongoDB 排序
sort() 方法
sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列
语法
db.COLLECTION_NAME.find().sort({key: 1})
案例
ruochen 集合中的数据按字段 likes 的降序排列
db.ruochen.find().sort({‘likes’: -1}).pretty()
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
MongoDB 索引
creatIndex() 方法
MongoDB使用 createIndex() 方法来创建索引
语法
db.collection.createIndex(keys, options)
Key 值为你要创建的索引字段, 1 为指定按升序创建索引, -1 为降序创建索引
案例
db.ruochen.createIndex({‘title’: 1})
db.ruochen.createIndex({‘title’: 1, ‘description’: -1}) # 设置多个字段创建索引
createIndex() 接收可选参数,可选参数列表如下
MongoDB聚合
MongoDB聚合(aggregate)主要用于处理数据(诸如统级平均值、求和等), 并返回计算后的数据结果。有点类似sql语句中的count(*)
aggregate() 方法
语法
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
实例
db.ruochen.aggregate([{group: {_id: "by", num_tutorial: {$sum: 1}}}])
类似于mql语句
select by, count(*) from ruochen group by by
聚合表达式
管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理
管道操作是可以重复的
表达式:处理文档并输出
表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档
常用操作
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档
m
a

t
c
h
:用于过滤数据,只输出符合条件的文档。
match:用于过滤数据,只输出符合条件的文档。
match:用于过滤数据,只输出符合条件的文档。match使用MongoDB的标准查询操作
$limit:用来限制MongoDB聚合管道返回的文档数
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
$group:将集合中的文档分组,可用于统计结果
$sort:将输入文档排序后输出
$geoNear:输出接近某一地理位置的有序文档
举例
$project
db.ruochen.aggregate( { $project: { title: 1, by: 1, }} ); 只剩_id, title 和 by 三个字段,默认_id 字段被包含 db.ruochen.aggregate( { $project: { _id: 0 title: 2, by: 1, }} ); 如此即可不包含_id, 非0可表示显示字段,负数也可以表示显示该字段
$match
获取分数大于70或小于等于90的记录,然后把符合条件的记录送到下一阶段$group 管道操作符进行处理 db.ruochen.aggregate([ {$match: {score: {$gt: 70, $lte: 90}}}, {$group: {_id: null, count: {$sum: 1}}} ])
当 match 条件和 group 同时存在时,顺序会影响检索结果,必须先写 match 在前面
$skip
过滤前5个文档 db.ruochen.aggregate( {$skip: 5});
MongoDB 数据库 数据结构
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



