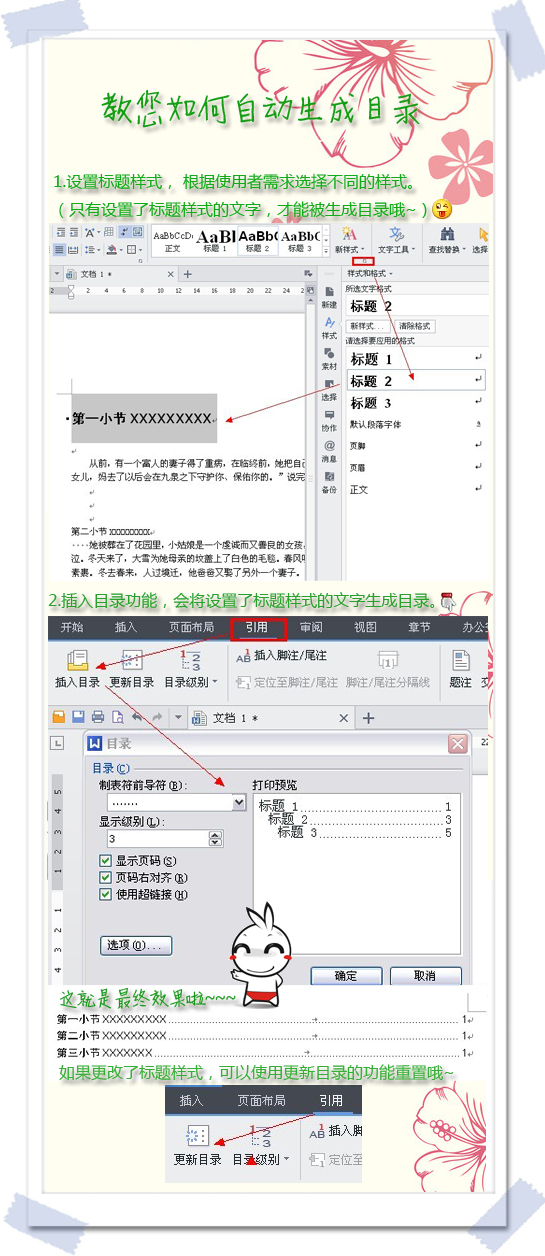
如何快速选中当前页(如何快速选中内容)
658
2022-05-29

相信在看了上一篇博客《带你快速认识NamenodeHA和Yarn HA,为搭建HadoopHA集群打下基础!》后,大家一定对于如何搭建HA集群非常期待٩(๑❛ᴗ❛๑)۶不要慌,本篇博客即将为大家带来搭建HA集群的详细教程!
码字不易,先赞后看!
文章目录
Hadoop HA集群的搭建
友情提示
<1> 安装配置Hadoop集群
① 备份集群
② 解压新的集群
③ 配置HDFS
④ 修改core-site.xml
⑤ 修改hdfs-site.xml
⑦ 修改mapred-site.xml
⑧修改yarn-site.xml
⑨修改slaves
⑩配置免密登录
<2> 启动各项进程
① 启动zookeeper集群
② 手动启动journalnode
③ 格式化namenode
④格式化ZKFC(在active上执行即可)
⑤ 启动HDFS(在node01上执行)
⑥ 启动YARN
<3> 浏览器访问
<4> 拓展
Hadoop HA集群的搭建
以下所有的操作均是有Hadoop集群的基础上执行的
。建议第一次安装集群的朋友先去看这篇博客《Hadoop(CDH)分布式环境搭建》,先搭建起一个正常可用的集群,再看这篇博客《zookeeper的安装详解》在集群上安装好了Zookeeper后再来看这篇
进阶
的博客。
<1> 安装配置Hadoop集群
因为我们事先已经搭建好了一个集群,所以我们需要先把之前的hadoop集群关闭。
stop-all.sh
然后将之前的hadoop所在的目录进行备份(三台节点)
cd /export/servers/
mv mv hadoop-2.6.0-cdh5.14.0 hadoop-2.6.0-cdh5.14.0_bk
进入到hadoop安装包所在的目录,重新解压。
cd /export/softwares/
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz -C ../servers/
需要注意的是,hadoop2.0所有的配置文件都在
$HADOOP_HOME/etc/hadoop
目录下
这一步本该是做一些添加系统环境变量之类的操作,但因为我们在之前的集群中就已经完成了这些操作,所以这一步的内容就可以直接跳过了~这也是为什么我推荐你们先搭建好一个集群的原因。
进入到指定的目录下:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
编辑core-site.xml,添加如下配置
vim core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
vim hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
先备份一份
cp mapred-site.xml.template mapred-site.xml
编辑mapred-site.xml,添加如下内容
1
2
3
4
5
6
7
修改yarn-site.xml,添加如下内容:
vim yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
vim slaves
node01 node02 node03
1
2
3
4
将软件拷贝到所有节点
这里是用scp命令,当然xsync可是可以的~
scp -r hadoop-2.6.0-cdh5.14.0 node02:/$PWD
scp -r hadoop-2.6.0-cdh5.14.0 node03:/$PWD
这里需要对主备节点配置免密登录,但因为我们在安装原始集群的时候已经配置好了,所以这一步也可以跳过了~
#首先要配置node01到node01、node02、node03 的免密码登陆
#在node01上生产一对钥匙
ssh-keygen
#将公钥拷贝到其他节点,包括自己
ssh-coyp-id node01
ssh-coyp-id node02
ssh-coyp-id node03
#注意:两个namenode之间要配置ssh免密码登陆 ssh远程补刀时候需要
#在node02上生产一对钥匙
ssh-keygen
#将公钥拷贝到node01
ssh-coyp-id node01
<2> 启动各项进程
严格按照下面的步骤,否则不能保证一定能成功
分别在node01,node02,node03节点上启动zookeeper
bin/zkServer.sh start #查看状态:一个leader,两个follower bin/zkServer.sh status
1
2
3
分别在在node01、node02、node03上执行
hadoop-daemon.sh start journalnode #运行jps命令检验,node01、node02、node03上多了JournalNode进程
1
2

#在node01上执行命令: hdfs namenode -format #格式化后会在根据core-site.xml中的hadoop.tmp.dir配置的目录下生成个hdfs初始化文件, hadoop.tmp.dir配置的目录下所有文件拷贝到另一台namenode节点所在的机器 scp -r tmp/ node02:/home/hadoop/app/hadoop-2.6.4/
1
2
3
4
5
6
hdfs zkfc -formatZK
1
start-dfs.sh
1
start-yarn.sh 还需要手动在standby上手动启动备份的 resourcemanager yarn-daemon.sh start resourcemanager
1
2
3
<3> 浏览器访问
配置完上述,用jps查看当前进程
[root@node01 helloworld]# jps 14305 QuorumPeerMain 15186 NodeManager 14354 JournalNode 14726 DataNode 20887 Jps 15096 ResourceManager 15658 NameNode 14991 DFSZKFailoverController
1
2
3
4
5
6
7
8
9
终于可以用浏览器进行访问了~
访问node01
http://node01:50070
可以发现当前该节点namenode的状态为Active
访问node02
http://node02:50070
可以发现当前该节点namenode的状态为(standby)
说明我们的HA集群部署成功了~
接下来我们向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
通过UI界面可以看到新的文件上传上来了
然后再kill掉active状态节点(也就是node01)的NameNode
kill -9
这个时候我们通过浏览器访问node02
http://node02:50070
发现node01"宕机"之后,node02的namenode处于Active的状态!
在node02节点运行下列命令,可以发现集群的数据跟node01宕机前是一样的。
hadoop fs -ls / -rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
1
2
刚刚我们手动"干掉"了node01节点上的namenode,现在我们手动启动它。
hadoop-daemon.sh start namenode
前面验证了HA,现在我们来认证一下Yarn!
任意一个节点,运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar wordcount /profile /out
看到上述的效果图,说明我们的HA集群算是搭建成功了!!!
<4> 拓展
OK大功告成!下面拓展一些测试HA集群的命令
hdfs dfsadmin -report 查看hdfs的各节点状态信息 hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态 hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
1
2
3
4
5
本次分享就到这里,受益的小伙伴或对大数据技术感兴趣的朋友不妨关注一下博主~
互相学习,共同进步!
Hadoop XML
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。