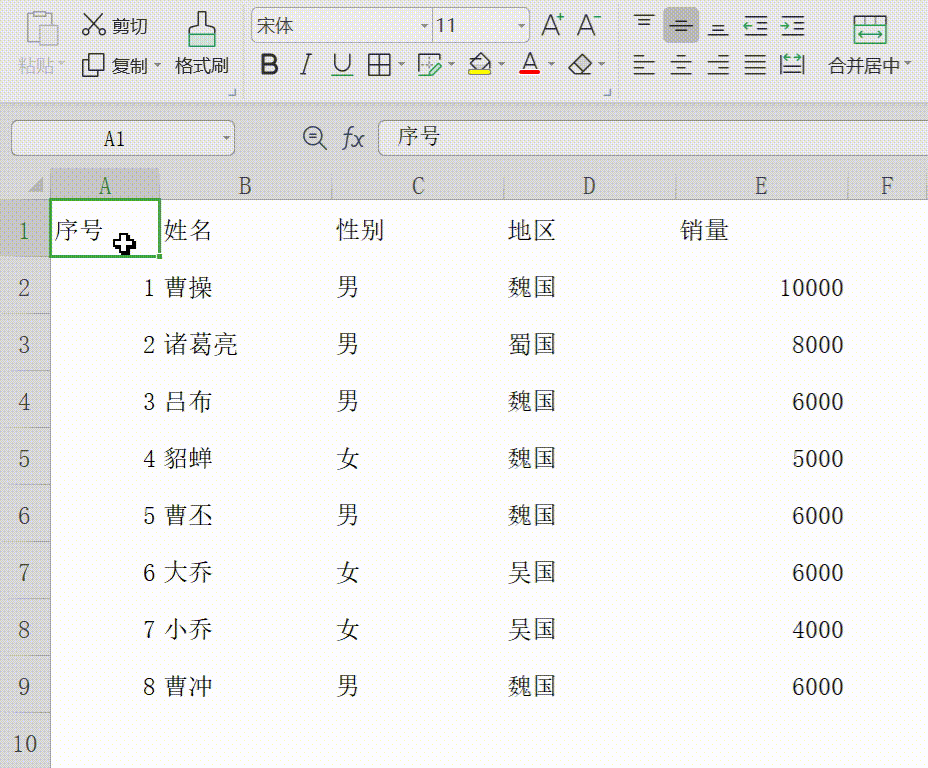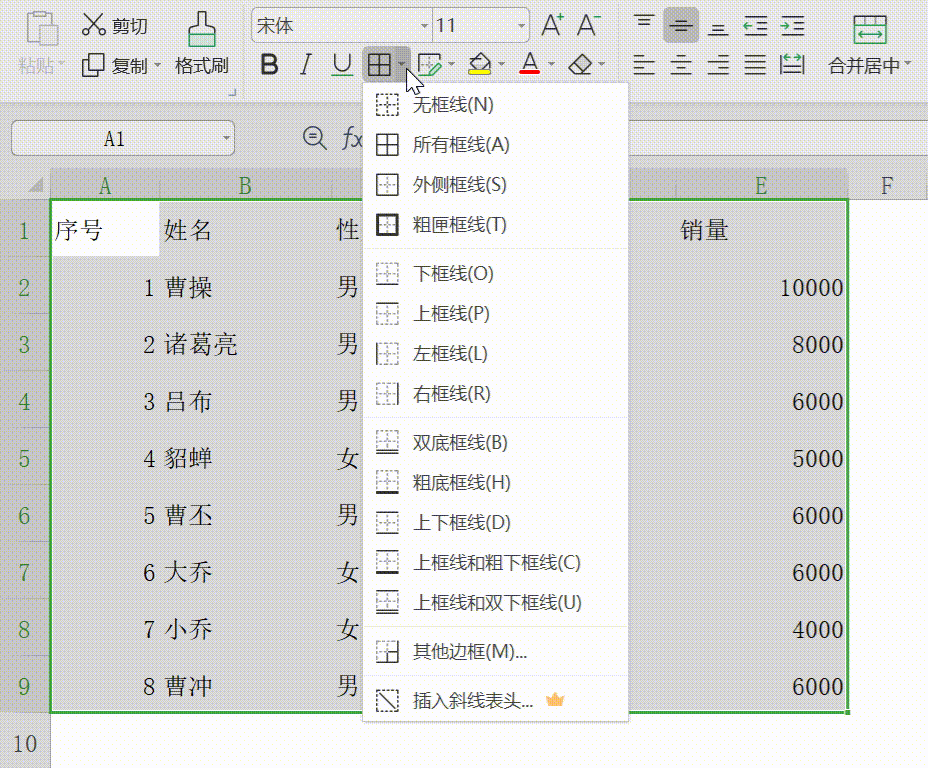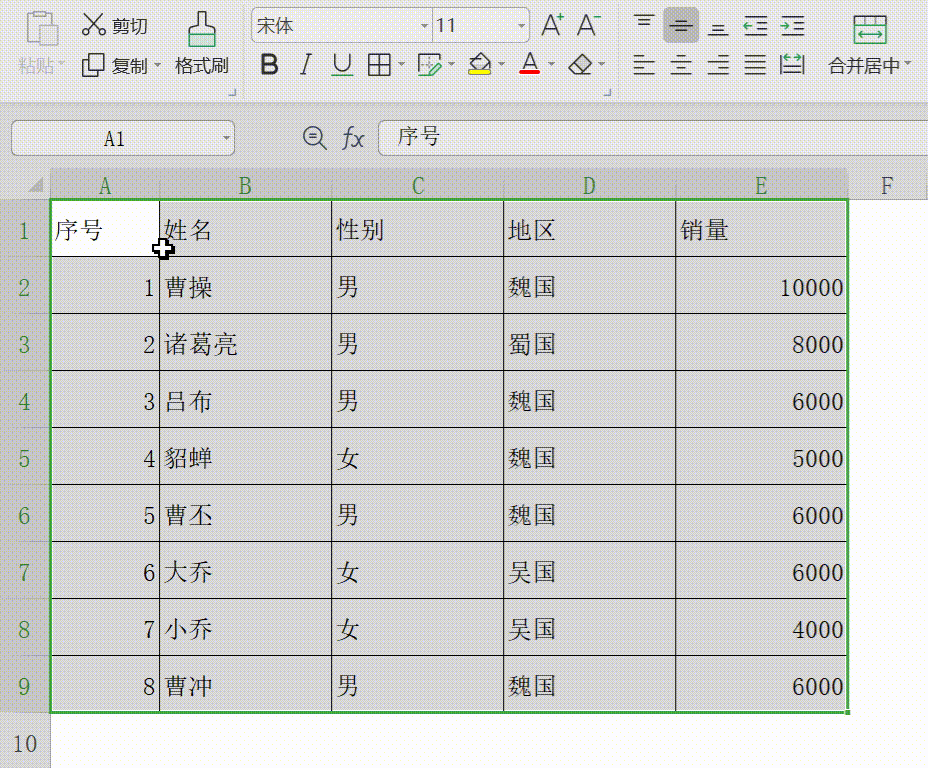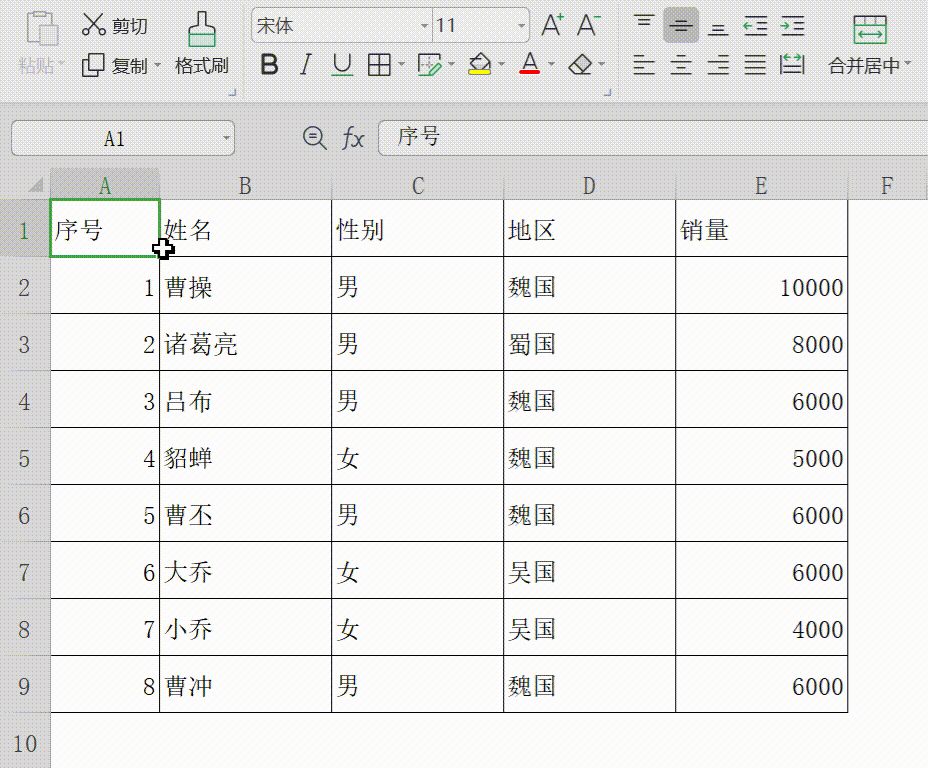
办公软件三剑客——Excel表格 可视化数据,excel表格制作教程入门,及常用公式
557
2022-05-29

话不多说我直接上干货
概念知识
安全模式是HDFS所处的一种特殊状态,在处于这种状态时,文件系统只接受读数据请求,不能对文件进行写,删除等操作。
在NameNode主节点启动时,HDFS首先进入安全模式,DataNode会向NameNode上传它们数据块的列表,让NameNode得到数据块的位置信息,并对每个文件对应的数据块副本进行统计。当最小副本条件满足时,即数据块都达到最小副本数,HDFS自动离开安全模式。这样就达到了资源的最大化利用,CPU的整合利用。
HDFS为每一个用户都创建了类似操作系统的回收站(Trash),位置在/user/用户名/.Trash/。当用户删除文件时,文件并不是马上被永久性删除,会被保留在回收站一段时间,这个保留的时间是可以设置的。
Hdfs的快照(snapshot)是在某一时间点对指定文件系统拷贝,快照采用只读模式,可以对重要数据进行恢复、防止用户错误性的操作。快照又分为两种:(1)建立文件系统的索引,每次更新文件不会真正的改变文件,而是新开辟一个空间来保存已经更改的文件。例如hdfs也是属于这样的,而且它的特性如下:新建快照的时候,Datanode中的block不会被复制,快照中只是记录了文件块的列表和大小信息,其次每个快照最高限额为65536个文件或者文件夹,在快照的子文件夹中不允许在创建新的快照,最后mv命令和del命令是不允许的,因为快照是只读的。(2)拷贝所有文件系统。至于如何开启快照和禁用快照,外援资料显示,因为一般是禁用的。
YARN的架构是主从架构,主机为ResourceManager,从机为NodeManager,其中ResourceManager负责接收客户端的作业请求以及为作业分配相应的NodeManager资源,在NodeManager启动Container资源容器,在资源容器中运行相关作业。
YARN架构中的Container容器,YARN管理的资源包括内存、CPU、磁盘、IO等等。Container是YARN中资源的抽象,它封装了某个节点上的多维度资源。
ResourceManger负责整个系统的资源分配和管理,是一个全局的资源管理器。主要由两个组件构成,分别是:调度器和应用程序管理器:调度器会根据资源情况为应用程序分配封装在Container中的资源,应用程序管理器负责管理整个系统中所有应用程序。
NodeManager是每个节点上的资源和任务管理器。NodeManager负责的工作有如下两点:定时向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态。接收并处理来自ApplicationManager的Container启动/停止等请求。
YARN中的应用是如何运行的:应用从客户端节点提交到YARN应用到资源管理器,然后资源管理查看集群里资源情况,在资源空闲的NodeManager节点启动ApplicationMaster作为管理该应用,ApplicationMaster分析计算是否有足够的资源运行任务,如果够,则自己处理;如果不够,则向资源管理器申请新的资源,当拿到新资源后,在新的资源所在的NodeManager启动资源容器,然后执行具体的作业任务。
YARN调度器分为三种:FIFO Scheduler先进先出调度器,Capacity Scheduler 容器调度器,Fair Scheduler 公平调度器
MapReduce框架把复杂的、运行于大规模集群上的计算过程高度抽象到两个函数Map和Reduce函数,我们只需要编写好Map和Reduce函数就能完成分布式计算。这样就是我们的分布式编程极大的简化了,帮我们隐藏了很多并行编程的细节。MapReduce最终要的策略就是分而治之的思想,比如说我们有个文件里面存的全是数字,MapReduce就会按照一定的规则把这个文件划分成一小块一小块的,然后把这些一小块的数据首先交给Map函数进行处理,然后Map函数的输出,然后作为Reduce函数的输入,Reduce处理后,然后进行输出
对于MapReduce,目前较为受欢迎的是Python为编程语言的设计语言,我们可以通过引流的方式对不同的数据进行处理。
Hbase的定义是一个分布式的,面向列的数据库。
Hbase与hdfs的本质区别就是HBASE可以结构化数据,而hdfs只能存储文件,对于HBASE存储数据的时候与我们的基本表有一个不同的就是,它有一个列族,而这个列族管理的列可以提高我们数据索引的效率。
一个表会包含很多行数据,每行数据都有行键,行键必须唯一,用于区分其他行,一个行中可以有很多列,这些列通过列族来分类。列族是多个列的集合。 其实列式数据库只需要列就可以了, 为什么还需要有列族呢? 因为HBase会尽量把同一个列族的列放到同一个服务器上, 这样可以提高存取性能, 并且可以批量管理有关联的一堆列。
hbase操作
安全模式,查看当前的状态:hdfs dfsadmin -safemode get
进入安全模式:hdfs dfsadmin -safemode enter
强制离开安全模式:hdfs dfsadmin -safemode leave
一直等待直到安全模式结束:hdfs dfsadmin -safemode wait
在hdfs里面输入命令,与Linux里面类似。只是需要在命令行开头加-
查看该目录下的子文件,递归查询:hdfs dfs -ls -R /home
")
移动文件夹或者文件:hdfs dfs -mv 源文件的位置 目标位置(如果是目录文件夹需要在后面加入/ 如果是文件则不需要)
递归删除home目录下的子文件或者子目录:hdfs dfs -rm -r /home/文件
删除目录需要把参数改为d即可
创建多级文件夹需要加-P参数,如果父目录不存在,则创建父目录
新建文件:hdfs dfs -touchz /whw/whw.txt 然后我们可以利用:hdfs dfs ls -R /whw 查看
上传文件:首先要在本地上面创建一个文件,注意这个时候不需要再touch后加z,我们创建好之后,利用:hdfs dfs -put 本地文件位置 hdfs目标位置,也可以利用:hdfs dfs -copyFromLocal 本地文件位置 hdfs目标位置
移动文件:hdfs dfs -moveFromLocal 本地文件位置 hdfs目标位置
将hdfs上的文件下载到本地位置:hdfs dfs -get hdfs的位置 本地目标位置/重命名,也可以用hdfs dfs -copyToLocal hdfs的位置 本地目标位置
查看文件:hdfs dfs -cat 文件位置
追写文件:hdfs dfs -appendToFile 本地文件 hdfs文件(两者都是相同的文件类型)
Hdfs里面的文件复制:hdfs dfs -cp 源文件 复制文件 参数:-f 如果目标文件存在则强制覆盖。-p保留文件的属性,移动文件(改名文件):hdfs dfs -mv 源文件 目标文件
Hdfs中的目录下的文件(不包含子目录)合并后在下载到本地:hdfs dfs -getmerge 本地文件(位置默认,不需要添加)
HBASE命令集合
启动HBASE,进入HBASE:start-hbase.sh habse shell
查询HBASE里面含有哪些表:list(注意和hive要有所区别,不能在后面加分号)。
创建表:create ‘表名’,’列族1’,’列族2’,’列族3’
添加一个列族:alter ‘表名称’,‘列族’
删除列族:alter ‘表名称’, {NAME => ‘列族名称’, METHOD => 'delete’}
禁止使用或者屏蔽这个表:disable ‘表名称’
删除表之前必须要禁止使用这个表,所以必须先要执行上面的操作,然后:drop ‘表名称’
启用表:enable ‘表名称’
查看这个表的结构:describe ‘表名称’
检查表是否存在:exists ‘表名称’
添加数据:put ‘表名称’,’行键’,’列族:列名1,列名2……’,‘数据1,数据2……’在这里我们就可以理解为是一个二维表,也就是Excel类似的,一行一列确定一个单元格
查询数据:get ‘表名称’,‘行键’
删除数据:delete ‘表名称’,‘行键’,‘列名称’这样就确定了一个数据集
删除一行数据:delete ‘表名称’,‘行键’
查看表中的记录数:count ‘表名称’
查看整张表:scan ‘表名称’(类似于MySQL里面的select)
扫描整个列族:scan ‘表名称’, {COLUMN=>‘列族’}
扫描一张表里面某个列的所有数据:scan ‘表名称’,{COLUMNS=>‘列族名:列名称’}
限制查询结果行数:scan ‘表名称’, { STARTROW => ‘rowkey1’, LIMIT=>行数, VERSIONS=>版本数}
等值过滤:scan ‘表名称’, FILTER=>"ValueFilter(=,‘binary:某值’)"过滤改值
HBASE实验操作
首先将本地数据文件上传到hdfs:hdfs dfs -put(copyFromLocal) /home/hadoop/ matchinfo.csv /lol
在执行次命令前,必须要在hdfs上创建一个lol文件夹;hdfs dfs -mkdir /lol
启动hbase 进入hbase:start-hbase.sh hbase shell
创建表和列族:create ‘lol_match’,’info’
导入数据到hbase中:
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=, -Dimporttsv.columns=“info:League,info:Year,info:Season,info:Type,info:blueTeamTag,info:bResult,info:rResult,info:redTeamTag,info:gamelength,info:blueTop,info:blueTopChamp,info:blueJungle,info:blueJungleChamp,info:blueMiddle,info:blueMiddleChamp,info:blueADC,info:blueADCChamp,info:blueSupport,info:blueSupportChamp,info:redTop,info:redTopChamp,info:redJungle,info:redJungleChamp,info:redMiddle,info:redMiddleChamp,info:redADC,info:redADCChamp,info:redSupport,info:redSupportChamp,HBASE_ROW_KEY” lol_match /lol/matchinfo.csv
每文一语
懂得越多才发现,不多的太多了
Hadoop HBase
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



