
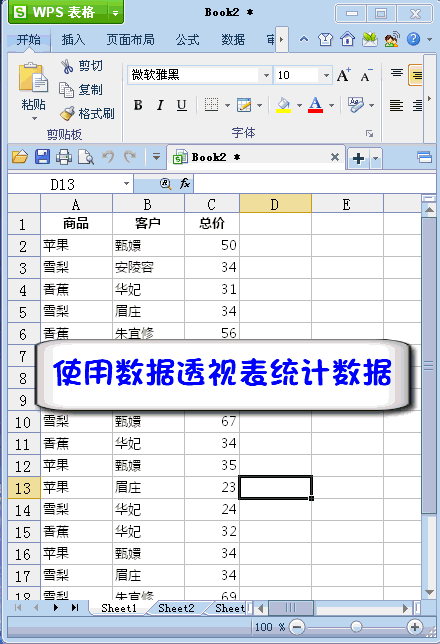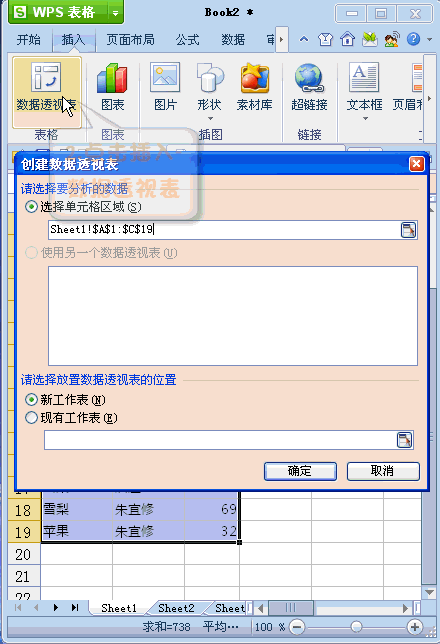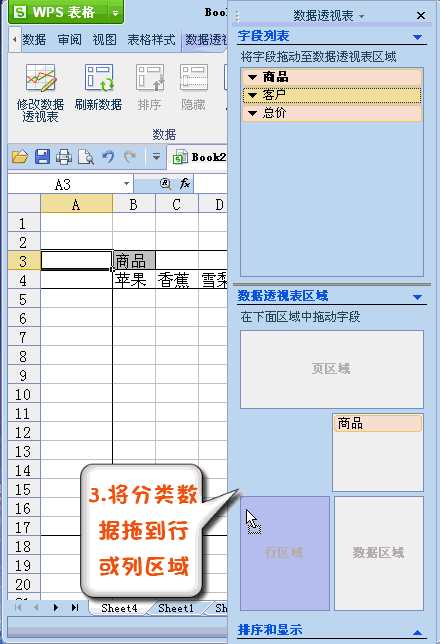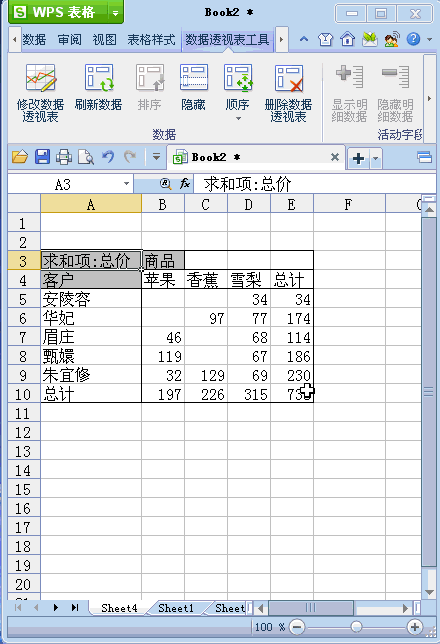
数据透视怎么弄(数据透视怎么做)
1060
2022-05-29

Hadoop YARN 将 Hadoop 的存储单元,即 HDFS(Hadoop 分布式文件系统)与各种处理工具结合在一起。对于那些你们谁是全新的这个话题,纱代表“ Ÿ等一诺特尔[R esource ñ egotiator”。我还建议您在继续学习 Apache Hadoop YARN 之前先阅读我们的Hadoop 教程和MapReduce 教程。我将在这里解释以下主题,以确保在本博客的末尾您对 Hadoop YARN 的理解是清晰的。
为什么是纱线?
Hadoop YARN 简介
YARN的组成部分
在 YARN 中提交申请
Hadoop YARN 中的应用程序工作流
为什么是纱线?
在 Hadoop 1.0 版(也称为 MRV1(MapReduce 版本 1))中,MapReduce 执行处理和资源管理功能。它由一个 Job Tracker 组成,它是一个单一的 master。作业-分配资源、执行调度并监控处理作业。它在称为任务-的许多从属进程上分配映射和化简任务。任务-定期向作业-报告他们的进度。
由于单个作业-,此设计导致可扩展性瓶颈。 IBM 在其文章中提到,根据 Yahoo! 的说法,这种设计的实际限制达到了 5000 个节点和 40,000 个并发运行任务的集群。 除了这个限制之外,MRV1 中计算资源的利用效率很低。此外,Hadoop 框架仅限于 MapReduce 处理范式。
为了克服所有这些问题,雅虎和 Hortonworks 于 2012 年在 Hadoop 2.0 版中引入了 YARN。YARN 背后的基本思想是通过接管资源管理和作业调度的责任来减轻 MapReduce。YARN 开始赋予 Hadoop 在 Hadoop 框架内运行非 MapReduce 作业的能力。
随着 YARN 的引入,Hadoop 生态系统 发生了彻底的变革。它变得更加灵活、高效和可扩展。当雅虎在 2013 年第一季度启用 YARN 时,它帮助该公司将其 Hadoop 集群的规模从 40,000 个节点缩小到 32,000 个节点。但工作岗位数量翻了一番,达到每月 2600 万个。
Hadoop YARN 简介
现在我已经启发了您对 YARN 的需求,让我向您介绍 Hadoop v2.0 的核心组件YARN。YARN 允许使用不同的数据处理方法,如图形处理、交互处理、流处理以及批处理来运行和处理存储在 HDFS 中的数据。因此,YARN 向 MapReduce 之外的其他类型的分布式应用程序开放了 Hadoop。
YARN 使用户能够通过使用各种工具(例如用于实时处理的Spark、用于 SQL 的Hive、用于 NoSQL 的HBase 等)来根据需要执行操作。
除了资源管理,YARN 还执行作业调度。YARN 通过分配资源和调度任务来执行您的所有处理活动。Apache Hadoop YARN 架构由以下主要组件组成:

资源管理器: 在主守护进程上运行并管理集群中的资源分配。
节点管理器:它们在从属守护进程上运行,负责在每个数据节点上执行任务。
Application Master: 管理用户作业生命周期和单个应用程序的资源需求。它与节点管理器一起工作并监视任务的执行。
容器: 单个节点上的资源包,包括 RAM、CPU、网络、HDD 等。
YARN的组成部分
您可以将 YARN 视为 Hadoop 生态系统的大脑。下图表示 YARN 架构。
YARN 架构的第一个组件是,
资源管理器
它是资源分配的最终权威。
在接收到处理请求时,它相应地将部分请求传递给相应的节点管理器,在那里进行实际的处理。
它是集群资源的仲裁者,决定为竞争应用程序分配可用资源。
优化集群利用率,例如根据容量保证、公平性和 SLA 等各种限制,始终保持所有资源处于使用状态。
它有两个主要组件: a) 调度器 b ) 应用程序管理器
a) 调度器
调度器负责将资源分配给受容量、队列等约束的各种正在运行的应用程序。
它在 ResourceManager 中被称为纯调度程序,这意味着它不会对应用程序执行任何状态监控或跟踪。
如果出现应用程序故障或硬件故障,调度程序不保证重新启动失败的任务。
根据应用程序的资源需求执行调度。
它有一个可插拔的策略插件,负责在各种应用之间划分集群资源。有两个这样的插件: Capacity Scheduler 和 Fair Scheduler,目前在ResourceManager中作为Scheduler使用。
b) 应用程序管理器
它负责接受工作提交。
协商来自资源管理器的第一个容器,用于执行特定于应用程序的 Application Master。
管理在集群中运行的 Application Master,并提供在故障时重新启动 Application Master 容器的服务。
来到第二个组件,即:
它负责处理 Hadoop 集群中的各个节点,并 管理给定节点上的用户作业和工作流。
它向资源管理器注册并发送带有节点健康状态的心跳。
它的主要目标是管理资源管理器分配给它的应用程序容器。
它与资源管理器保持同步。
应用程序主机通过向节点管理器发送容器启动上下文 (CLC) 来从节点管理器请求分配的容器,其中包含应用程序运行所需的一切。节点管理器创建请求的容器进程并启动它。
监控单个容器的资源使用情况(内存、CPU)。
执行日志管理。
它还按照资源管理器的指示杀死容器。
Apache Hadoop YARN的第三个组件是,
应用程序是提交给框架的单个作业。每个这样的应用程序都有一个与之关联的唯一应用程序主机,它是一个特定于框架的实体。
它是协调应用程序在集群中执行并管理故障的过程。
它的任务是从资源管理器协商资源,并与节点管理器一起执行和监控组件任务。
它负责从 ResourceManager 协商适当的资源容器,跟踪它们的状态并监控进度。
一旦启动,它会定期向资源管理器发送心跳以确认其健康状况并更新其资源需求记录。
该第四成分是:
它是单个节点上的物理资源的集合,例如 RAM、CPU 内核和磁盘。
YARN 容器由容器生命周期 (CLC) 的容器启动上下文管理。该记录包含环境变量映射、存储在远程访问存储中的依赖项、安全令牌、节点管理器服务的有效负载以及创建进程所需的命令。
它授予应用程序使用特定主机上特定数量资源(内存、CPU 等)的权利。
在 YARN 中提交申请
请参阅图像并查看提交 Hadoop YARN 应用程序所涉及的步骤:
1)提交作业
2) 获取应用程序 ID
3) 申请提交上下文
4 a) 启动容器 启动
b) 启动 Application Master
5) 分配资源
6 a) 容器
b) 启动
7) 执行
Hadoop YARN 中的应用程序工作流
参考给定的图像并查看 Apache Hadoop YARN 的应用程序工作流中涉及的以下步骤:
客户提交申请
Resource Manager 分配一个容器来启动Application Manager
应用程序管理器向资源管理器注册
应用程序管理器向资源管理器询问容器
应用程序管理器通知节点管理器启动容器
应用程序代码在容器中执行
客户端联系资源管理器/应用程序管理器以监控应用程序的状态
应用程序管理器向资源管理器取消注册
Hadoop Yarn
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



