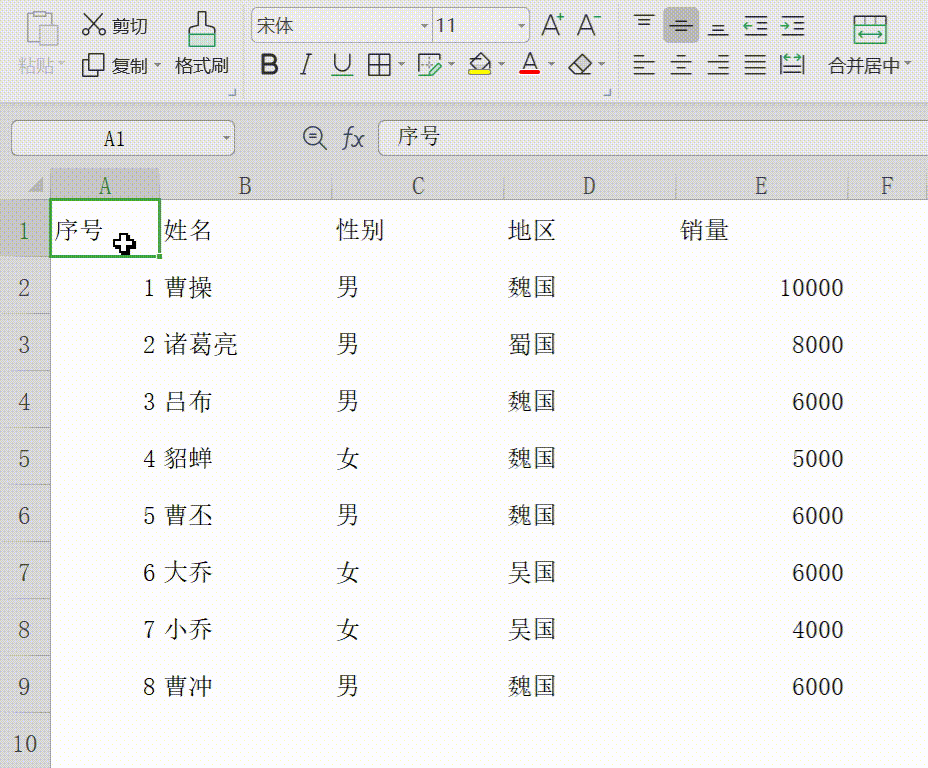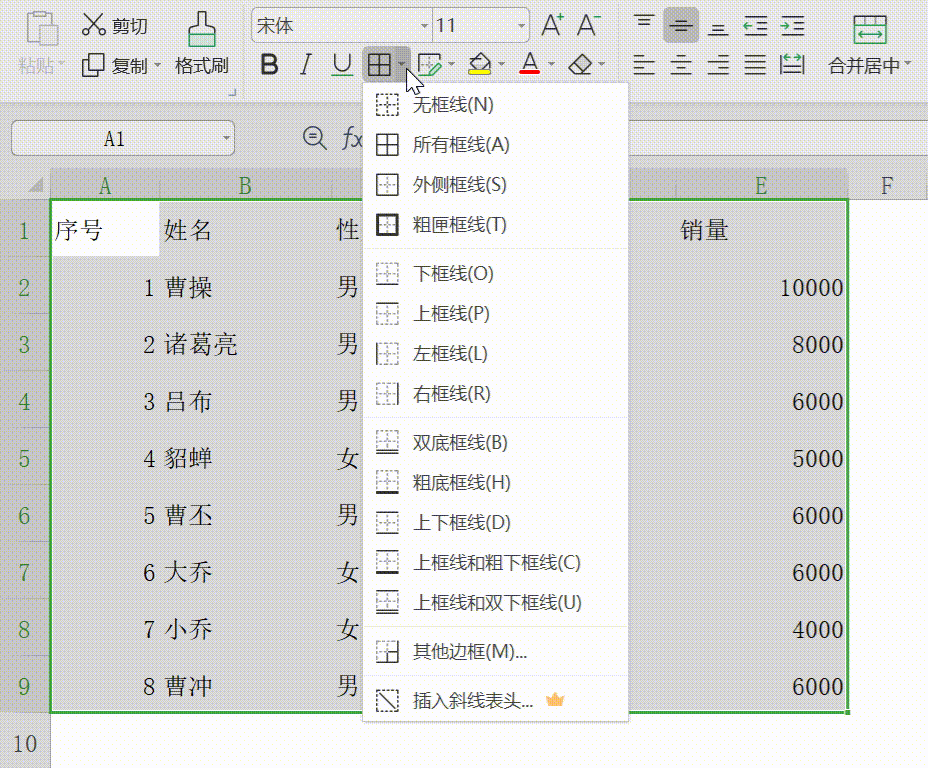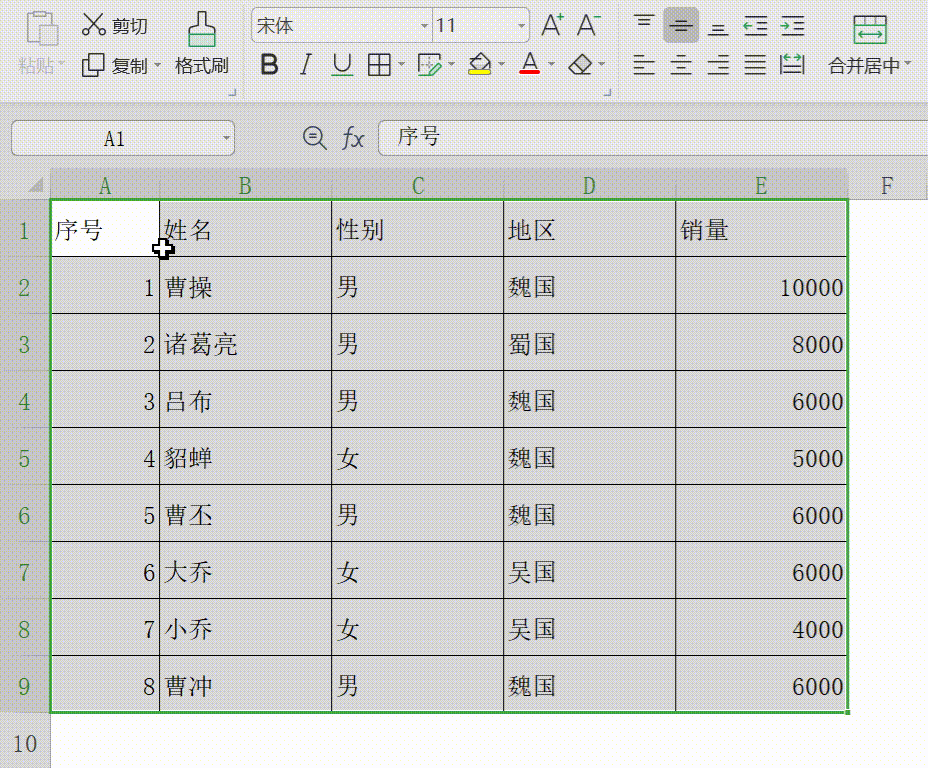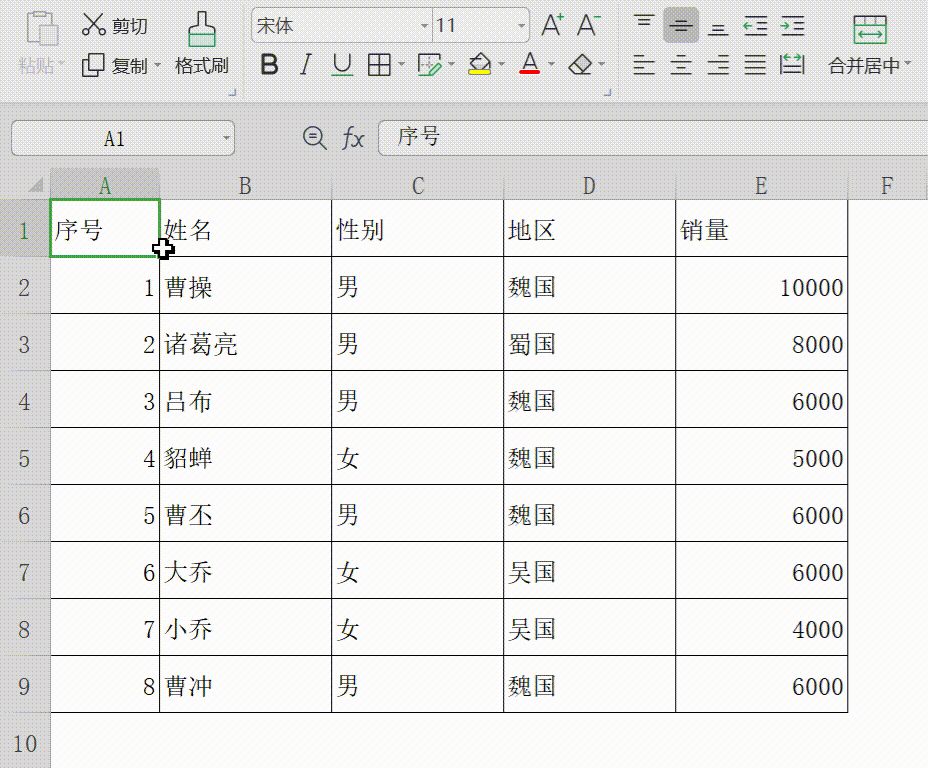
办公软件三剑客——Excel表格 可视化数据,excel表格制作教程入门,及常用公式
720
2022-05-29

最近在跟着朋友们学习看股票,股票确实蛮复杂的,一堆的指标,各种乱七八糟的线,玩了有两周,买了几个股票,基本上算是持平。虽然看了各种劝退的视频,但是感觉还是挺有意思的,继续学习股票的相关知识。选股很重要,虽然我不会,但是在网上看了一些视频,看到了一些个策略,因为自己是最近在学习爬虫,手里有个锤子看什么都是钉子,所以想着用自己学习的python爬取数据,做个简单的筛选,好了,开始吧。
1、需求分析
目标网站:东方财富网
网址:https://www.eastmoney.com/
看!全部都是腐臭的金钱的气味,呵!万恶的金钱。
找到A股的市场行情页面:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
因为刚开始学习股票,所以怎么筛选也不懂,那就跟着朋友给的简单的几个筛选条件。
筛选股票的条件:
1、筛选上涨的股票,上涨的区间在 2% - 6% 的,追涨但是不追那种涨的太多的
2、换手率在1% -10%,剔除不活跃的股票,没有交易的股票是没有价值的
3、挑选市值在50-500亿之间的股票,因为太大的资金盘,主力没办法拉升
4、去除创业板,因为我的是新手期账户,所以去除30开始的股票
2、流程分析
1、爬取网页,读取所有的股票数据
2、分析数据,取出需要的股票代码,股票涨跌幅,总市值,以及详细股票信息的链接
3、过滤数据,筛选出最终的股票
4、保存所有的数据到文件中,这样可以保留历史数据,也可以接下来做其他的分析。
3、数据分析
因为股票数据是分页的,所以在爬取的过程中需要分页读取
方案就是在数据框中输入对应的页数,然后点go 进行爬取,右键selector 获取css 选择器
先获得所有的行,通过xpath 进行获取
//*[@id="table_wrapper-table"]/tbody/tr[1] 去除最后的下标,得到所有的行数据 //*[@id="table_wrapper-table"]/tbody/tr
因为要读取市值这个指标,所以需要对下拉框进行勾选
s1 = Select(driver.find_element_by_id('custom-fields')) # 实例化Select s1.select_by_value("FlowCapitalValue")
在开始的时候对每页点击完成之后就继续读取下一页的数据了,没有等待数据加载完成,造成报错
使用了driver.implicity_wait(10),发现没有用,因为当前页面已经加载完成,但是这个方式可以研究,猜想可能可以选择对应的元素
最后只能自己做了,因为页面上有个当前选择的标签,就一直等待当前选择的页码和页面上渲染的当前页码相匹配就认为数据加载完成。
csv 文件的格式可以用Excel打开,可以处理,同时也写入简单,所以选择了csv ,
csv 的文件个是 逗号 进行分开字段,换行进行换行,你可以实现在txt 文件中写入1,2,3,4 ,保存之后,修改扩展名为a.csv
4、show you code
用到的环境:

python 3,seleunim
环境的安装可以参考 https://mp.weixin.qq.com/s?__biz=MzA4ODczMDIzNQ==&mid=2447776747&idx=1&sn=925169d8b3a8e680413c74e848f1ec71&chksm=843704ffb3408de912394e34fb51bc831e357473c6882d90fe3df2b674c171e35c4ad0ca5b79&token=2091426734&lang=zh_CN#rd
定义一下要保存的数据结构:
#!/usr/bin/env python # encoding: utf-8 """ #Author: 香菜 @time: 2021/8/21 0021 下午 4:33 """ class StockData: def __init__(self,id,code,up,link,switch,markValue): self.id = id self.code = code self.up = up self.link = link self.switch = switch self.markValue = markValue
主要的爬取代码
#!/usr/bin/env python # encoding: utf-8 import datetime import time import requests from selenium import webdriver from selenium.webdriver.support.select import Select from xin.stock.StockData import StockData """ #Author: 香菜 @time: 2021/8/21 0021 下午 4:03 """ BASE_URL = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board" # 涨幅 UP_MIN = 2 UP_MAX = 7 # 量比 LIANG_MIN = 1 # 市值 VALUE_MIN = 50 VALUE_MAX = 200 # 换手率 SWITCH_MIN = 1 SWITCH_MAX = 10 # 市值 MARK_VALUE_MIN= 50 MARK_VALUE_MAX= 300 selectCode = [] # 将 5% 转为 5 def percent2Float(percentStr): return float(percentStr[:len(percentStr) - 1]) def write2Csv(): dateTime_p = datetime.datetime.now() str_p = datetime.datetime.strftime(dateTime_p, '%Y_%m_%d') fileName = 'stock' + str_p + '.csv' with open(fileName, 'a+', encoding='utf-8') as f: f.write('id,code,涨幅,换手率,流通市值,详细地址\r\n') for data in selectCode: line = data.id + ','\ + data.code + ','\ + data.up + ','\ + data.switch + ','\ + data.markValue+ ',' \ + data.link + ',' +'\r\n' f.write(line) if __name__ == '__main__': driver = webdriver.Chrome('E:\child\python\python\chromedriver.exe') driver.get(BASE_URL) s1 = Select(driver.find_element_by_id('custom-fields')) # 实例化Select s1.select_by_value("FlowCapitalValue") i = 1 pageFinish = False for i in range(1,231): onePageRowList = driver.find_elements_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr') for row in onePageRowList: tdList = row.find_elements_by_tag_name('td') id = tdList[0].text # id code = tdList[1].text # 股票代码 up = percent2Float(tdList[5].text) # 涨幅 link = tdList[1].find_element_by_tag_name('a').get_attribute('href') switchStr = tdList[14].text # 换手率 markValue = tdList[len(tdList)-2].text # 市值 if switchStr == '-': continue switch = percent2Float(tdList[14].text) if code.startswith('30'): continue if up < UP_MIN: pageFinish = True break if up > UP_MAX: continue if switch < SWITCH_MIN or switch > SWITCH_MAX: continue markV = float(markValue[:len(markValue)-1]) if markV < MARK_VALUE_MIN or markV > MARK_VALUE_MAX: continue selectCode.append(StockData(id,code,tdList[5].text,link,switchStr,markValue)) if pageFinish: break # 换下一页 pageInput = driver.find_element_by_css_selector('#main-table_paginate > input') pageInput.clear() pageInput.send_keys(str(i)) goBtn = driver.find_element_by_css_selector('#main-table_paginate > a.paginte_go') goBtn.click() print("当前页码:"+ str(i)) # 等待加载完成 while True: curPageStr = driver.find_element_by_css_selector('#main-table_paginate > span.paginate_page > a.paginate_button.current').text curPage = int(curPageStr) if curPage == i: time.sleep(0.5) break else: time.sleep(0.5) # 写入到csv write2Csv()
代码里有基本的注释,我猜你应该看的懂,看不懂的话可以留言给我,或者加我微信,我们一起学习
5、爬取结果
可以看到结果已经实现了我第一步的需求,还不错,至少能参考一下,总比自己一页一页的翻找方便了
总结:
这只是走出了选股的第一步,后面还有很多指标需要过滤,继续获取数据,并且可以使用深度学习进行优化,路还很长。
还有炒股有风险,入市需谨慎,小赌怡情,大赌伤身。切记
【百变AI秀】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/296704
AI Python
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



