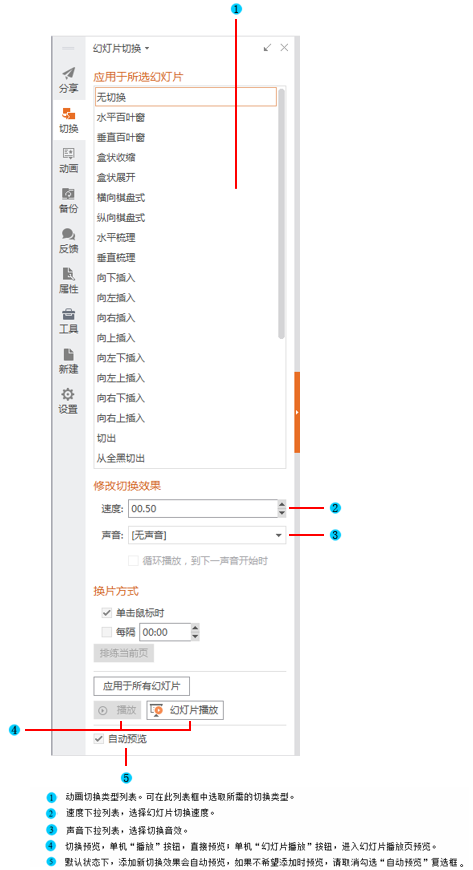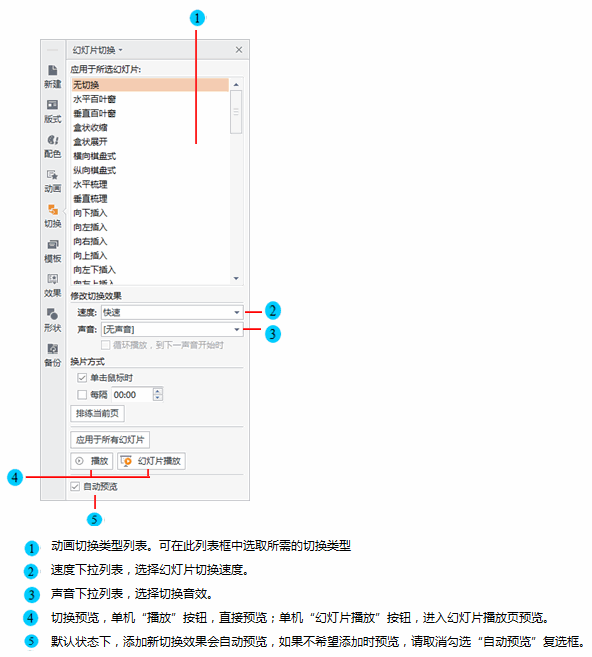
如何让一张幻灯片中的内容一个一个出来(制作幻灯片时,怎样让答案一个一个出来)
1039
2022-05-29

答:分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)
答:在传统的文件系统中,为了提高磁盘读写效率,一般以数据块为单位,而不是以字节为单位。
HDFS中的块,默认一个块大小为64MB,而HDFS中的文件会被拆分成多个块,每个块作为独立的单元进行存储。HDFS在块的大小的设计上明显要大于普通文件系统。
答:名称节点负责管理分布式文件系统系统的命名空间,记录分布式文件系统中的每个文件中各个块所在的数据节点的位置信息;
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并向名称节点定期发送自己所存储的块的列表。
hadoop fs -ls
显示
指定的文件的详细信息
hadoop fs -cat
将
指定的文件的内容输出到标准输出
hadoop fs -mkdir
创建
指定的文件夹
hadoop fs -get [-ignorecrc] [-crc] 复制指定的文件到本地文件系统指定的文件或文件夹。-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
hadoop fs -put 从本地文件系统中复制指定的单个或多个源文件到指定的目标文件系统中。也支持从标准输入(stdin)中读取输入写入目标文件系统。
hadoop fs -rmr
删除

指定的文件夹及其的所有文件
Hadoop 大数据
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。