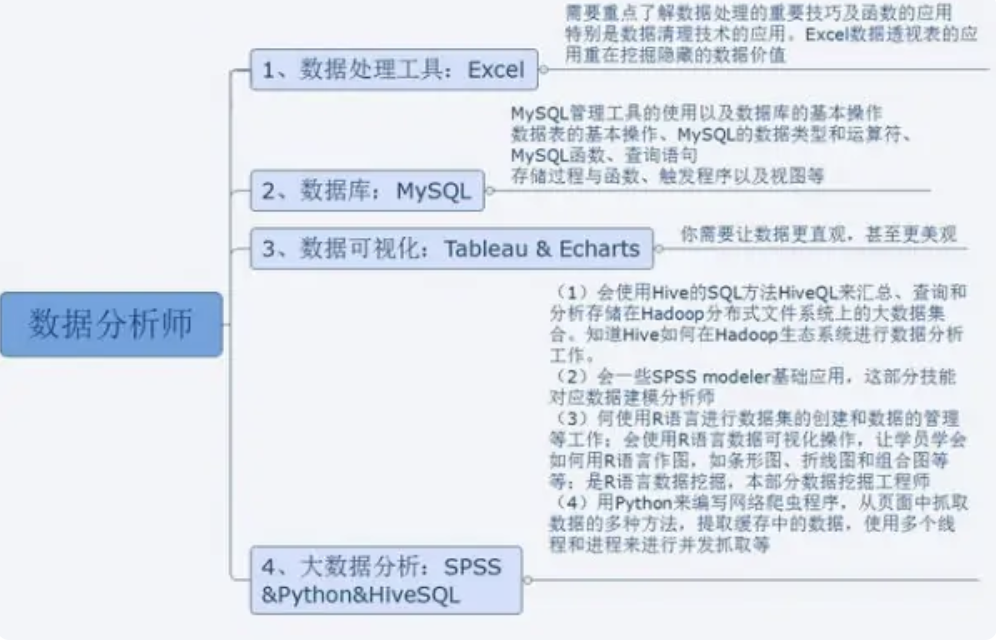
宜收藏:5款常用的数据分析工具,简单便捷!数据分析工具常见的有哪些?
743
2022-05-29

在给用户画像做定义之前,我们先来了解一下什么是推荐系统
场景:
在现在的互联网时代,网上购物已经称为常态,当我们在各大电商平台购物的时候,不难发现这样一个现象。当你搜索某个上面进行浏览的时候,点击目标商品,之后返回到首页,很大概率你就可以发现,你刚才搜索的商品的相关产品已经在首页的推荐栏目。例如,你购买了一件护肤品面霜,回到首页推荐处,系统可能就会给你推荐口红或者相关护肤品。又例如当你搜索用户画像书籍的时候,推荐栏目就会出现有关用户画像的书籍。这些功能就叫做推荐,而完成这些行为的即为推荐系统。
本质:
推荐系统就是对用户的浏览行为进行记录分析,并基于这些行为对用户将要购买的商品进行预测。老王购买了用户画像的书籍,那么老王便与这本书之间产生一个连接。小丽购买了护肤品,那么小丽便于这个护肤品之间产生了连接。而推荐系统就是根据一些算法去预测用户与商品之间还未产生的连接。
来看一张简单的用户画像表:
给用户画像下定义:
用户画像是对用户的一种标注,通过给用户打上标签的形式来描述用户
这个标签可以是一个人的年龄,性别,收入情况,也可以是一个人的购物倾向或者是常居住地
总而言之我们能想到的用来描述一个人的各方面特征的都可以算作是画像的范畴
画像表相对比较稀疏,一般一个用户画像的项目至少有近百个标签,而大部分用户都应该只打上一部分呢标签,所以总体来说画像表应该较为稀疏
大部分标签使用ID进行匹配查找,定位到用户标签再找到用户群体
进行聚合统计的需求较多

需要数据库可以按key查询,聚合统计查询,以及多条件组合查询
稀疏表的储存不应该占用太多空间资源
mysql这个数据库大家应该都不陌生,这里我们从这个数据库的底层结构开始说起,mysql底层所选用的数据结构为B+树,说到B+树这里就不得不提一下另一种数据结构B数
B树介绍:
上图是一个 B树 的形式, 每个节点有两个数据元素, 每个节点有三个子节点, 每个叶子节点有两个数据元素
无论是什么形式的 B树, 都具备以下定理, 这四个定理也是保证 B树 插入和删除能够平衡的原因
根节点至少两个子节点
每个中间节点都包含 m 个孩子, 每个中间节点都包含 m - 1 个数据元素
最底层的节点称之为叶子节点, 所有叶子节点都位于同一层
所有节点中的数据元素按照大小排列, 所有子节点按照数据元素的大小排列, 父节点的数据元素恰好是子节点数据元素的值域划分点
B树插入规则:
如果当前节点未满, 插入
如果当前节点已满, 分裂节点, 中间大小的值提升, 直到插入根节点
如果根节点也已满, 插入节点成为新的根节点, 层级 +1
B树存在的问题:
因为 B树 中所有节点都可携带数据元素, 所以导致性能不稳定
范围查找效率太低
基于B树存在的这些问题,B+树出现了
B+树:
B+树的特性:
有 k 个子树的中间节点, 就可以存放 K 个数据元素(比 B树 多一个)
中间节点不保存数据, 只用来索引, 划分子树值域, 所有数据元素都以卫星的形式和叶子节点关联
叶子节点本身按照 Key 有序
所有中间节点的元素都存在于子节点
B+数的优点:
单一节点存储更多的元素, IO 次数变少
所有查询都要查找到叶子节点, 看起来每次都是都是最差情况, 但是三层的 B+树 可以存放一百万条数据, 通常 B+树 都很低很宽
所有叶子节点是形成有序链表, 范围查询性能极强
B+树与MySql的关系:
聚集索引:
非聚集索引:
MySQL的索引类型:
在 MySQL 中, 有两个引擎, 如下
MyISAM,引擎, 事务支持很差, 较少使用
InnoDB,引擎, 事务支持完备, 使用较广泛
InnoDB 的特点
任何一张表的数据都自带一个聚集索引
默认情况下, 建表必须有主键, 默认的聚集索引以主键为 Key
总的来说,无论是否聚集, MySQL 中的索引都是 B+树 结构
MySQL特性总结:
根据 B+树 的特性可以知道, 每次在插入的时候都比较复杂, 当数据量增多的时候, 性能衰减会非常明显
B+树 是查找树, 其节点之间是有序的, 当需要搜索的时候, 时间复杂度和折半查找一样, 只有 Log2N
B+树 的叶子节点构成了一个类似链表的结构, 所以进行范围查找的时候, 不需要回到父节点, 可以直接在子节点中进行, 所以在进行一些复杂查询的时候比较方便范围取数据
因为 MySQL 的主要目的是 OLTP, OLTP 更强调每次操作一条或者多条数据, 所以 MySQL 是行存储的形式, 行存储为了对齐所有的列, 即使某列为 Null, 也依然会有按照数据类型的占位
MySQL存在的问题:
插入性能会随着树的复杂度而递减
数据多的话会导致树变得很宽,这个时候插入数据就复杂度就变高了
随着数据量不断增加,树从插入性能就下架了
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,参考谷歌的BigTable后使用java语言进行了实现。也是Apache软件基金会的Hadoop项目的一部分,可以运行运行在HDFS文件系统容错地存储海量稀疏的数据。
先来说说LSM-Tree
LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用了,磁盘批量的顺序写要远比随机写性能高出很多。
如图为LSM-Tree日志合并树
当我们的log以这种格式写入的时候,全部都是以Append的模式追加的,不存在删除和修改,这种结构虽然大大提升了数据的写入能力,但是以牺牲部分读取性能为代价,索引这种结构通常适合于写多读少的场景。故LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量。
Hbase与LSM-Tree
HBase 的一个表有多个 Region 分布在多个 RegionServer 上, 一个 RegionServer 有多个 Region
每个 Region 又分为 Memstore 和 DiskStore, 其实就是 LSM树
HBase 的存储结构是 Key-Value
虽然 HBase 对外提供的看起来好像一种表, 但其实在 Region 中, 数据以 KV 的形式存在
一级缓存: BlockCache
MySQL 的 B+树 并不是把数据直接存放在树中, 而是把数据组成 页(Page) 然后再存入 B+树, MySQL 中最小的数据存储单元是 Page
HBase 也一样, 其最小的存储单元叫做 Block, Block 会被缓存在 BlockCache 中, 读数据时, 优先从 BlockCache 中读取
BlockCache 是 RegionServer 级别的
BlockCache 叫做读缓存, 因为 BlockCache 缓存的数据是读取返回结果给客户端时存入的
二级缓存: 当查找数据时, 会先查内存, 后查磁盘, 然后汇总返回
因为写是写在 Memstore 中, 所以从 Memstore 就能立刻读取最新状态
Memstore 没有的时候, 扫描 HFile, 通过布隆过滤器优化读性能
综上所述:
HBase 是 LSM树 的一种开源实现, 类似的还有 LevelDB, RocketDB 等
HBase 无论是批量写还是实时写, 性能都超过 MySQL 不少
HBase 的查询只有一种, 就是扫描, Get 也是扫描的一种特殊情况, 所以 HBase 的查询能力不强
HBase 以 KV 的形式存储数据, 所以如果某一单元数据为 Null 则不存, 所以 HBase 适合存储比较稀疏的表
对上面所提到的数据库再进行一次总结:
MySQL
随着数据的增多, 插入性能递减
查找延迟低
范围查询优势明显, 可以实现复杂的查询
完整存储所有数据, 不适合稀疏表
Hbase
HBase 无论是批量写还是实时写, 性能都超过 MySQL 不少
HBase 的查询只有一种, 就是扫描, Get 也是扫描的一种特殊情况, 所以 HBase 的查询能力不强
HBase 以 KV 的形式存储数据, 所以如果某一单元数据为 Null 则不存, 所以 HBase 适合存储比较稀疏的表
MySQL VS Hbase
从存储形式上来看, 选 HBase, HBase 是 KV 型数据库, 是不需要提前预设 Schema 的, 添加新的标签时候比较方便
从使用方式上来看, 选 MySQL 似乎更好, 但是 HBase 也可以, 因为并没有太多复杂查询
从写入方式上来看, 选 HBase, 因为画像的数据一般量也不小, HBase 可以存储海量数据, 而 MySQL 不太适合集群部署
总结:
最终选择的方案为HBase,其实在大数据的生态圈中还存在着很多数据储存的工具,例如Hive,ES等等,在特定的情况下这些输出储存工具也是可取的。
大数据
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



