
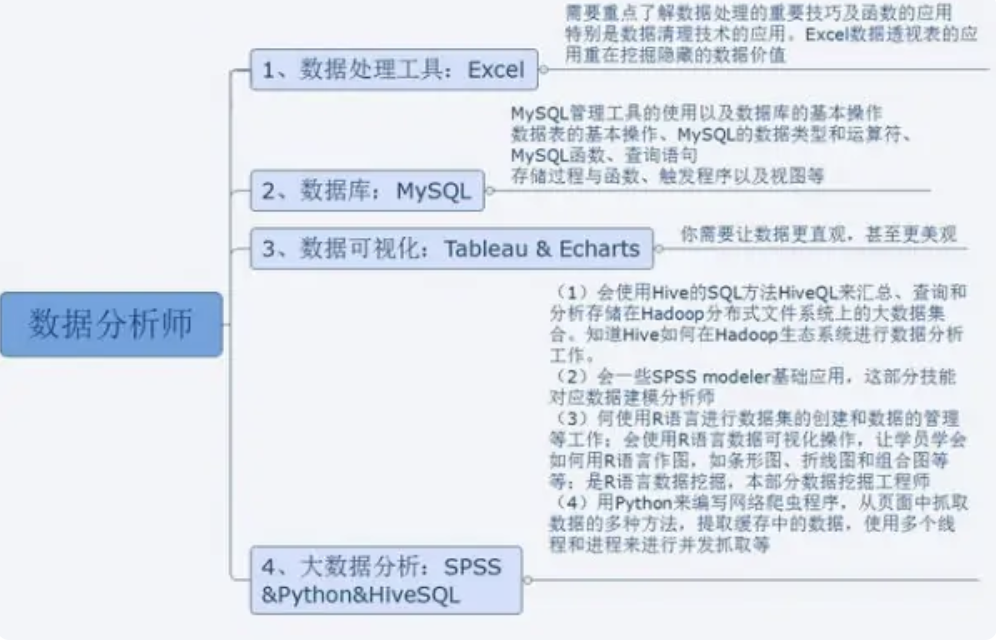
宜收藏:5款常用的数据分析工具,简单便捷!数据分析工具常见的有哪些?
729
2022-05-29

算子调优一:mapPartitions
普通的 map 算子对 RDD 中的每一个元素进行操作,而 mapPartitions 算子对 RDD 中每一个分区进行操作。如果是普通的 map 算子,假设一个 partition 有 1 万条数据, 那么 map 算子中的 function 要执行 1 万次, 也就是对每个元素进行操作。

图 2-3 map 算子
image.png
图 2-4 mapPartitions 算子
image.png
mapPartitions 算子也存在一些缺点:对于普通的 map 操作,一次处理一条数据, 如果在处理了 2000 条数据后内存不足, 那么可以将已经处理完的 2000 条数据从内存中垃圾回收掉; 但是如果使用 mapPartitions 算子,但数据量非常大时, function 一次处理一个分区的数据,如果一旦内存不足,此时无法回收内存,就可能会 OOM, 即内存溢出。
因 此 , mapPartitions 算 子 适 用 于 数 据 量 不 是 特 别 大 的 时 候 , 此 时 使 用mapPartitions 算子对性能的提升效果还是不错的。(当数据量很大的时候,一旦使用 mapPartitions 算子, 就会直接 OOM)
在项目中,应该首先估算一下 RDD 的数据量、每个 partition 的数据量,以及分配给每个 Executor 的内存资源,如果资源允许,可以考虑使用 mapPartitions 算子代替 map。
在生产环境中, 通常使用 foreachPartition 算子来完成数据库的写入,通过
foreachPartition 算子的特性, 可以优化写数据库的性能。
如果使用 foreach 算子完成数据库的操作,由于 foreach 算子是遍历 RDD 的每条数据,因此,每条数据都会建立一个数据库连接,这是对资源的极大浪费,因此,对于写数据库操作,我们应当使用 foreachPartition 算子。
与 mapPartitions 算子非常相似,foreachPartition 是将 RDD 的每个分区作为遍历对象,一次处理一个分区的数据,也就说,如果涉及数据库的相关操作,一个分区的数据只需要创建一次数据库连接,如图 2-5 所示:
image.png
对于我们写的 function 函数, 一次处理一整个分区的数据;
对于一个分区内的数据, 创建唯一的数据库连接;
只需要向数据库发送一次 SQL 语句和多组参数;
在 生 产 环 境 中 , 全 部 都 会 使 用 foreachPartition 算 子 完 成 数 据 库 操 作 。
foreachPartition 算子存在一个问题,与 mapPartitions 算子类似,如果一个分区的数据量特别大,可能会造成 OOM, 即内存溢出。
在 Spark 任务中我们经常会使用 filter 算子完成 RDD 中数据的过滤,在任务初始阶段,从各个分区中加载到的数据量是相近的,但是一旦进过 filter 过滤后,每个分区的数据量有可能会存在较大差异, 如图 2-6 所示:
image.png
针对第一个问题,既然分区的数据量变小了,我们希望可以对分区数据进行
重新分配,比如将原来 4 个分区的数据转化到 2 个分区中, 这样只需要用后面的两
个 task 进行处理即可,避免了资源的浪费。
针对第二个问题,解决方法和第一个问题的解决方法非常相似,对分区数据重新分配,让每个 partition 中的数据量差不多,这就避免了数据倾斜问题。
那么具体应该如何实现上面的解决思路? 我们需要 coalesce 算子。
repartition 与 coalesce 都可以用来进行重分区,其中 repartition 只是 coalesce 接口中 shuffle 为 true 的简易实现,coalesce 默认情况下不进行 shuffle,但是可以通过参数进行设置。
假设我们希望将原本的分区个数 A 通过重新分区变为 B,那么有以下几种情况:
A > B(多数分区合并为少数分区)
① A 与 B 相差值不大
此时使用 coalesce 即可,无需 shuffle 过程。
② A 与 B 相差值很大
此时可以使用 coalesce 并且不启用 shuffle 过程,但是会导致合并过程性能低下, 所以推荐设置 coalesce 的第二个参数为 true,即启动 shuffle 过程。
A < B(少数分区分解为多数分区)
此时使用 repartition 即可,如果使用 coalesce 需要将 shuffle 设置为 true,否则
coalesce 无效。
我们可以在 filter 操作之后,使用 coalesce 算子针对每个 partition 的数据量各不相同的情况,压缩 partition 的数量,而且让每个 partition 的数据量尽量均匀紧凑, 以便于后面的 task 进行计算操作, 在某种程度上能够在一定程度上提升性能。
注意:local 模式是进程内模拟集群运行,已经对并行度和分区数量有了一定的内部优化,因此不用去设置并行度和分区数量。
在第一节的常规性能调优中我们讲解了并行度的调节策略,但是,并行度的设置对于 Spark SQL 是不生效的, 用户设置的并行度只对于 Spark SQL 以外的所有Spark 的stage 生效。
Spark SQL 的并行度不允许用户自己指定,Spark SQL 自己会默认根据 hive 表对应的 HDFS 文件的 split 个数自动设置 Spark SQL 所在的那个 stage 的并行度, 用户自己通 spark.default.parallelism 参数指定的并行度, 只会在没 Spark SQL 的 stage 中生效。
由于 Spark SQL 所在 stage 的并行度无法手动设置, 如果数据量较大,并且此stage 中后续的 transformation 操作有着复杂的业务逻辑,而 Spark SQL 自动设置的task 数量很少, 这就意味着每个 task 要处理为数不少的数据量,然后还要执行非常复杂的处理逻辑,这就可能表现为第一个有 Spark SQL 的 stage 速度很慢,而后续的没有 Spark SQL 的 stage 运行速度非常快。
为了解决 Spark SQL 无法设置并行度和 task 数量的问题, 我们可以使用
repartition 算子。
image.png
图 2-7 repartition算子使用前后对比图
Spark SQL 这一步的并行度和 task 数量肯定是没有办法去改变了,但是, 对于Spark SQL 查询出来的 RDD, 立即使用 repartition 算子, 去重新进行分区, 这样可以重新分区为多个 partition,从 repartition 之后的 RDD 操作,由于不再涉及SparkSQL,因此 stage 的并行度就会等于你手动设置的值,这样就避免了 Spark SQL 所在的 stage 只能用少量的 task 去处理大量数据并执行复杂的算法逻辑。使用 repartition 算子的前后对比如图 2-7 所示。
reduceByKey 相较于普通的 shuffle 操作一个显著的特点就是会进行map 端的本地聚合,map 端会先对本地的数据进行 combine 操作,然后将数据写入给下个 stage 的每个 task 创建的文件中,也就是在 map 端,对每一个 key 对应的 value,执行reduceByKey 算子函数。reduceByKey 算子的执行过程如图 2-8 所示:
image.png
本地聚合后,在 map 端的数据量变少, 减少了磁盘 IO,也减少了对磁盘空间的占用;
本地聚合后,下一个 stage 拉取的数据量变少,减少了网络传输的数据量;
本地聚合后,在 reduce 端进行数据缓存的内存占用减少;
本地聚合后,在 reduce 端进行聚合的数据量减少。
基于 reduceByKey 的本地聚合特征, 我们应该考虑使用 reduceByKey 代替其他的 shuffle 算子,例如 groupByKey。reduceByKey 与 groupByKey 的运行原理如图 2-9 和图 2-10 所示:
image.png
图 2-9 groupByKey 原理
image.png
根据上图可知, groupByKey 不会进行 map 端的聚合, 而是将所有 map 端的数据 shuffle 到 reduce 端, 然后在 reduce 端进行数据的聚合操作。由于 reduceByKey 有 map 端 聚 合 的 特 性 , 使 得 网 络 传 输 的 数 据 量 减 小 , 因 此 效 率 要 明 显 高 于groupByKey。
我们建议,如果能通过reduceByKey就用reduceByKey,因为reducebykey会在map端,先进行本地的combine,可以大大减少要传输到reduce端的数据量,减小网络传输的开销。
ReduceByKey这个操作首先会在HashShufferWriter的write()方法,先判断一下,如果是 isMapCombined,那么就在本地聚合,聚合完以后在写入磁盘。
而groupbykey的性能,相对来说很低,因为他是不会进行本地聚合的,而是原封不动,把shufferMapTask的输出,拉取到ResultTask的内存中,所以这样的话,就会导致,所有的数据,都要进行网络传输,从而导致网络传输的性能开销特别大!
spark SQL
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



