


小白进阶之 Scrapy 第六篇 Scrapy-Redis 详解
Scrapy-Redis 详解
通常我们在一个站站点进行采集的时候,如果是小站的话 我们使用 scrapy 本身就可以满足。 但是如果在面对一些比较大型的站点的时候,单个 scrapy 就显得力不从心了。 要是我们能够多个 Scrapy 一起采集该多好啊 人多力量大。 很遗憾 Scrapy 官方并不支持多个同时采集一个站点,虽然官方给出一个方法: 将一个站点的分割成几部分 交给不同的 scrapy 去采集 似乎是个解决办法,但是很麻烦诶!毕竟分割很麻烦的哇 下面就改轮到我们的额主角 Scrapy-Redis 登场了!
什么??你这么就登场了?还没说为什么呢?
好吧 为了简单起见 就用官方图来简单说明一下: 这张图大家相信大家都很熟悉了。重点看一下 SCHEDULER 1. 先来看看官方对于 SCHEDULER 的定义: SCHEDULER 接受来自 Engine 的 Requests, 并将它们放入队列(可以按顺序优先级),以便在之后将其提供给 Engine 点我看文档 2. 现在我们来看看 SCHEDULER 都提供了些什么功能: 根据官方文档说明 在我们没有没有指定 SCHEDULER 参数时,默认使用:’scrapy.core.scheduler.Scheduler’ 作为 SCHEDULER (调度器) scrapy.core.scheduler.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
class Scheduler(object):
def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
logunser=False, stats=None, pqclass=None):
self.df = dupefilter
self.dqdir = self._dqdir(jobdir)
self.pqclass = pqclass
self.dqclass = dqclass
self.mqclass = mqclass
self.logunser = logunser
self.stats = stats
# 注意在scrpy中优先注意这个方法,此方法是一个钩子 用于访问当前爬虫的配置
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
# 获取去重用的类 默认:scrapy.dupefilters.RFPDupeFilter
dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])
# 对去重类进行配置from_settings 在 scrapy.dupefilters.RFPDupeFilter 43行
# 这种调用方式对于IDE跳转不是很好 所以需要自己去找
# @classmethod
# def from_settings(cls, settings):
# debug = settings.getbool('DUPEFILTER_DEBUG')
# return cls(job_dir(settings), debug)
# 上面就是from_settings方法 其实就是设置工作目录 和是否开启debug
dupefilter = dupefilter_cls.from_settings(settings)
# 获取优先级队列 类对象 默认:queuelib.pqueue.PriorityQueue
pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])
# 获取磁盘队列 类对象(SCHEDULER使用磁盘存储 重启不会丢失)
dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])
# 获取内存队列 类对象(SCHEDULER使用内存存储 重启会丢失)
mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])
# 是否开启debug
logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG'))
# 将这些参数传递给 __init__方法
return cls(dupefilter, jobdir=job_dir(settings), logunser=logunser,
stats=crawler.stats, pqclass=pqclass, dqclass=dqclass, mqclass=mqclass)
def has_pending_requests(self):
"""检查是否有没处理的请求"""
return len(self) > 0
def open(self, spider):
"""Engine创建完毕之后会调用这个方法"""
self.spider = spider
# 创建一个有优先级的内存队列 实例化对象
# self.pqclass 默认是:queuelib.pqueue.PriorityQueue
# self._newmq 会返回一个内存队列的 实例化对象 在110 111 行
self.mqs = self.pqclass(self._newmq)
# 如果self.dqdir 有设置 就创建一个磁盘队列 否则self.dqs 为空
self.dqs = self._dq() if self.dqdir else None
# 获得一个去重实例对象 open 方法是从BaseDupeFilter继承的
# 现在我们可以用self.df来去重啦
return self.df.open()
def close(self, reason):
"""当然Engine关闭时"""
# 如果有磁盘队列 则对其进行dump后保存到active.json文件中
if self.dqs:
prios = self.dqs.close()
with open(join(self.dqdir, 'active.json'), 'w') as f:
json.dump(prios, f)
# 然后关闭去重
return self.df.close(reason)
def enqueue_request(self, request):
"""添加一个Requests进调度队列"""
# self.df.request_seen是检查这个Request是否已经请求过了 如果有会返回True
if not request.dont_filter and self.df.request_seen(request):
# 如果Request的dont_filter属性没有设置(默认为False)和 已经存在则去重
# 不push进队列
self.df.log(request, self.spider)
return False
# 先尝试将Request push进磁盘队列
dqok = self._dqpush(request)
if dqok:
# 如果成功 则在记录一次状态
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 不能添加进磁盘队列则会添加进内存队列
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
def next_request(self):
"""从队列中获取一个Request"""
# 优先从内存队列中获取
request = self.mqs.pop()
if request:
self.stats.inc_value('scheduler/dequeued/memory', spider=self.spider)
else:
# 不能获取的时候从磁盘队列队里获取
request = self._dqpop()
if request:
self.stats.inc_value('scheduler/dequeued/disk', spider=self.spider)
if request:
self.stats.inc_value('scheduler/dequeued', spider=self.spider)
# 将获取的到Request返回给Engine
return request
def __len__(self):
return len(self.dqs) + len(self.mqs) if self.dqs else len(self.mqs)
def _dqpush(self, request):
if self.dqs is None:
return
try:
reqd = request_to_dict(request, self.spider)
self.dqs.push(reqd, -request.priority)
except ValueError as e: # non serializable request
if self.logunser:
msg = ("Unable to serialize request: %(request)s - reason:"
" %(reason)s - no more unserializable requests will be"
" logged (stats being collected)")
logger.warning(msg, {'request': request, 'reason': e},
exc_info=True, extra={'spider': self.spider})
self.logunser = False
self.stats.inc_value('scheduler/unserializable',
spider=self.spider)
return
else:
return True
def _mqpush(self, request):
self.mqs.push(request, -request.priority)
def _dqpop(self):
if self.dqs:
d = self.dqs.pop()
if d:
return request_from_dict(d, self.spider)
def _newmq(self, priority):
return self.mqclass()
def _newdq(self, priority):
return self.dqclass(join(self.dqdir, 'p%s' % priority))
def _dq(self):
activef = join(self.dqdir, 'active.json')
if exists(activef):
with open(activef) as f:
prios = json.load(f)
else:
prios = ()
q = self.pqclass(self._newdq, startprios=prios)
if q:
logger.info("Resuming crawl (%(queuesize)d requests scheduled)",
{'queuesize': len(q)}, extra={'spider': self.spider})
return q
def _dqdir(self, jobdir):
if jobdir:
dqdir = join(jobdir, 'requests.queue')
if not exists(dqdir):
os.makedirs(dqdir)
return dqdir
只挑了一些重点的写了一些注释剩下大家自己领会 (才不是我懒哦) 从上面的代码 我们可以很清楚的知道 SCHEDULER 的主要是完成了 push Request pop Request 和 去重的操作。 而且 queue 操作是在内存队列中完成的。 大家看 queuelib.queue 就会发现基于内存的(deque) 那么去重呢?
1
2
3
4
5
6
7
8

9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
# 此处可以看到去重其实打开了一个名叫 requests.seen的文件
# 如果是使用的磁盘的话
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
# 判断我们的请求是否在这个在集合中
return True
# 没有在集合就添加进去
self.fingerprints.add(fp)
# 如果用的磁盘队列就写进去记录一下
if self.file:
self.file.write(fp + os.linesep)
按照正常流程就是大家都会进行重复的采集;我们都知道进程之间内存中的数据不可共享的,那么你在开启多个Scrapy的时候,它们相互之间并不知道对方采集了些什么那些没有没采集。那就大家伙儿自己玩自己的了。完全没没有效率的提升啊!  怎么解决呢? 这就是我们Scrapy-Redis解决的问题了,不能协作不就是因为Request 和 去重这两个 不能共享吗? 那我把这两个独立出来好了。 将Scrapy中的SCHEDULER组件独立放到大家都能访问的地方不就OK啦!加上scrapy-redis后流程图就应该变成这样了? 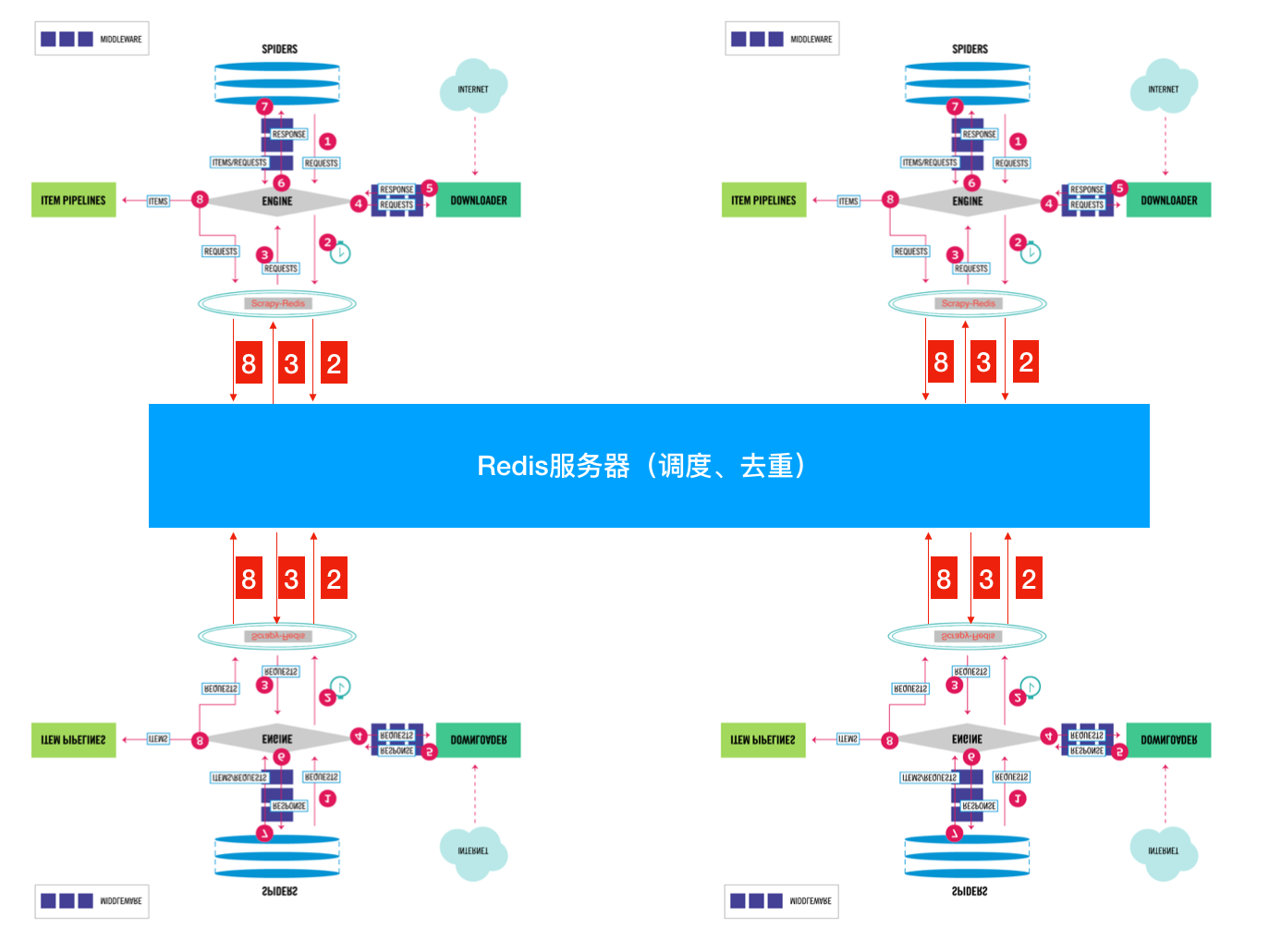 So············· 这样是不是看起来就清楚多了??? 下面我们来看看Scrapy-Redis是怎么处理的? scrapy_redis.scheduler.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
class Scheduler(object):
"""Redis-based scheduler
Settings
--------
SCHEDULER_PERSIST : bool (default: False)
Whether to persist or clear redis queue.
SCHEDULER_FLUSH_ON_START : bool (default: False)
Whether to flush redis queue on start.
SCHEDULER_IDLE_BEFORE_CLOSE : int (default: 0)
How many seconds to wait before closing if no message is received.
SCHEDULER_QUEUE_KEY : str
Scheduler redis key.
SCHEDULER_QUEUE_CLASS : str
Scheduler queue class.
SCHEDULER_DUPEFILTER_KEY : str
Scheduler dupefilter redis key.
SCHEDULER_DUPEFILTER_CLASS : str
Scheduler dupefilter class.
SCHEDULER_SERIALIZER : str
Scheduler serializer.
"""
def __init__(self, server,
persist=False,
flush_on_start=False,
queue_key=defaults.SCHEDULER_QUEUE_KEY,
queue_cls=defaults.SCHEDULER_QUEUE_CLASS,
dupefilter_key=defaults.SCHEDULER_DUPEFILTER_KEY,
dupefilter_cls=defaults.SCHEDULER_DUPEFILTER_CLASS,
idle_before_close=0,
serializer=None):
"""Initialize scheduler.
Parameters
----------
server : Redis
这是Redis实例
persist : bool
是否在关闭时清空Requests.默认值是False。
flush_on_start : bool
是否在启动时清空Requests。 默认值是False。
queue_key : str
Request队列的Key名字
queue_cls : str
队列的可导入路径(就是使用什么队列)
dupefilter_key : str
去重队列的Key
dupefilter_cls : str
去重类的可导入路径。
idle_before_close : int
等待多久关闭
"""
if idle_before_close < 0:
raise TypeError("idle_before_close cannot be negative")
self.server = server
self.persist = persist
self.flush_on_start = flush_on_start
self.queue_key = queue_key
self.queue_cls = queue_cls
self.dupefilter_cls = dupefilter_cls
self.dupefilter_key = dupefilter_key
self.idle_before_close = idle_before_close
self.serializer = serializer
self.stats = None
def __len__(self):
return len(self.queue)
@classmethod
def from_settings(cls, settings):
kwargs = {
'persist': settings.getbool('SCHEDULER_PERSIST'),
'flush_on_start': settings.getbool('SCHEDULER_FLUSH_ON_START'),
'idle_before_close': settings.getint('SCHEDULER_IDLE_BEFORE_CLOSE'),
}
# If these values are missing, it means we want to use the defaults.
optional = {
# TODO: Use custom prefixes for this settings to note that are
# specific to scrapy-redis.
'queue_key': 'SCHEDULER_QUEUE_KEY',
'queue_cls': 'SCHEDULER_QUEUE_CLASS',
'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY',
# We use the default setting name to keep compatibility.
'dupefilter_cls': 'DUPEFILTER_CLASS',
'serializer': 'SCHEDULER_SERIALIZER',
}
# 从setting中获取配置组装成dict(具体获取那些配置是optional字典中key)
for name, setting_name in optional.items():
val = settings.get(setting_name)
if val:
kwargs[name] = val
# Support serializer as a path to a module.
if isinstance(kwargs.get('serializer'), six.string_types):
kwargs['serializer'] = importlib.import_module(kwargs['serializer'])
# 或得一个Redis连接
server = connection.from_settings(settings)
# Ensure the connection is working.
server.ping()
return cls(server=server, **kwargs)
@classmethod
def from_crawler(cls, crawler):
instance = cls.from_settings(crawler.settings)
# FIXME: for now, stats are only supported from this constructor
instance.stats = crawler.stats
return instance
def open(self, spider):
self.spider = spider
try:
# 根据self.queue_cls这个可以导入的类 实例化一个队列
self.queue = load_object(self.queue_cls)(
server=self.server,
spider=spider,
key=self.queue_key % {'spider': spider.name},
serializer=self.serializer,
)
except TypeError as e:
raise ValueError("Failed to instantiate queue class '%s': %s",
self.queue_cls, e)
try:
# 根据self.dupefilter_cls这个可以导入的类 实例一个去重集合
# 默认是集合 可以实现自己的去重方式 比如 bool 去重
self.df = load_object(self.dupefilter_cls)(
server=self.server,
key=self.dupefilter_key % {'spider': spider.name},
debug=spider.settings.getbool('DUPEFILTER_DEBUG'),
)
except TypeError as e:
raise ValueError("Failed to instantiate dupefilter class '%s': %s",
self.dupefilter_cls, e)
if self.flush_on_start:
self.flush()
# notice if there are requests already in the queue to resume the crawl
if len(self.queue):
spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue))
def close(self, reason):
if not self.persist:
self.flush()
def flush(self):
self.df.clear()
self.queue.clear()
def enqueue_request(self, request):
"""这个和Scrapy本身的一样"""
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
# 向队列里面添加一个Request
self.queue.push(request)
return True
def next_request(self):
"""获取一个Request"""
block_pop_timeout = self.idle_before_close
# block_pop_timeout 是一个等待参数 队列没有东西会等待这个时间 超时就会关闭
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request
def has_pending_requests(self):
return len(self) > 0
来先来看看 以上就是 Scrapy-Redis 中的 SCHEDULER 模块。下面我们来看看 queue 和本身的什么不同: scrapy_redis.queue.py 以最常用的优先级队列 PriorityQueue 举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
"""其实就是使用Redis的有序集合 来对Request进行排序,这样就可以优先级高的在有序集合的顶层 我们只需要"""
"""从上往下依次获取Request即可"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
"""添加一个Request进队列"""
# self._encode_request 将Request请求进行序列化
data = self._encode_request(request)
"""
d = {
'url': to_unicode(request.url), # urls should be safe (safe_string_url)
'callback': cb,
'errback': eb,
'method': request.method,
'headers': dict(request.headers),
'body': request.body,
'cookies': request.cookies,
'meta': request.meta,
'_encoding': request._encoding,
'priority': request.priority,
'dont_filter': request.dont_filter,
'flags': request.flags,
'_class': request.__module__ + '.' + request.__class__.__name__
}
data就是上面这个字典的序列化
在Scrapy.utils.reqser.py 中的request_to_dict方法中处理
"""
# 在Redis有序集合中数值越小优先级越高(就是会被放在顶层)所以这个位置是取得 相反数
score = -request.priority
# We don't use zadd method as the order of arguments change depending on
# whether the class is Redis or StrictRedis, and the option of using
# kwargs only accepts strings, not bytes.
# ZADD 是添加进有序集合
self.server.execute_command('ZADD', self.key, score, data)
def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
有序集合不支持超时所以就木有使用timeout了 这个timeout就是挂羊头卖狗肉
"""
"""从有序集合中取出一个Request"""
# use atomic range/remove using multi/exec
"""使用multi的原因是为了将获取Request和删除Request合并成一个操作(原子性的)在获取到一个元素之后 删除它,因为有序集合 不像list 有pop 这种方式啊"""
pipe = self.server.pipeline()
pipe.multi()
# 取出 顶层第一个
# zrange :返回有序集 key 中,指定区间内的成员。0,0 就是第一个了
# zremrangebyrank:移除有序集 key 中,指定排名(rank)区间内的所有成员 0,0也就是第一个了
# 更多请参考Redis官方文档
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
以上就是 SCHEDULER 在处理 Request 的时候做的操作了。 是时候来看看 SCHEDULER 是怎么处理去重的了! 只需要注意这个?方法即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
# 通过self.request_fingerprint 会生一个sha1的指纹
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
# 添加进一个Redis集合如果self.key这个集合中存在fp这个指纹会返回1 不存在返回0
added = self.server.sadd(self.key, fp)
return added == 0
这样大家就都可以访问同一个Redis 获取同一个spider的Request 在同一个位置去重,就不用担心重复啦 大概就像这样:
spider1:检查一下这个 Request 是否在 Redis 去重,如果在就证明其它的 spider 采集过啦!如果不在就添加进调度队列,等待别 人获取。自己继续干活抓取网页 产生新的 Request 了 重复之前步骤。
spider2:以相同的逻辑执行
可能有些小伙儿会产生疑问了~~!spider2 拿到了别人的 Request 了 怎么能正确的执行呢?逻辑不会错吗? 这个不用担心啦 因为整 Request 当中包含了,所有的逻辑,回去看看上面那个序列化的字典。 总结一下:
1. Scrapy-Reids 就是将 Scrapy 原本在内存中处理的 调度 (就是一个队列 Queue)、去重、这两个操作通过 Redis 来实现
多个 Scrapy 在采集同一个站点时会使用相同的 redis key(可以理解为队列)添加 Request 获取 Request 去重 Request,这样所有的 spider 不会进行重复采集。效率自然就嗖嗖的上去了。
3. Redis 是原子性的,好处不言而喻 (一个 Request 要么被处理 要么没被处理,不存在第三可能)
另外 Scrapy-Redis 本身不支持 Redis-Cluster,大量网站去重的话会给单机很大的压力(就算使用 boolfilter 内存也不够整啊!) 改造方式很简单:
使用 rediscluster 这个包替换掉本身的 Redis 连接
Redis-Cluster 不支持事务,可以使用 lua 脚本进行代替(lua 脚本是原子性的哦)
注意使用 lua 脚本 不能写占用时间很长的操作(毕竟一大群人等着操作 Redis 你总不能让人家等着吧)
以上!完毕 对于懒人小伙伴儿 看看这个我改好的: 集群版 Scrapy-Redis PS: 支持 Python3.6+ 哦 ! 其余的版本没测试过
Redis Scrapy
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章

推荐文章
最近发表
- 宠物集市在深圳哪里有?时间地址最新消息
- 亚洲宠物展2025年展会介绍
- 京宠展信息指南
- 宠物展会2025年时间表
- 亚宠展、全球宠物产业风向标——亚洲宠物展览会深度解析
- 2025年亚洲宠物展览会、京宠展有哪些亮点
- wps演示添加自定义按钮设置动作改变按顺序播放" href="https://www.huoban.com/news/post/118206.html">wps演示添加自定义按钮设置动作改变按顺序播放
- WPS行中的文本调整到行中" href="https://www.huoban.com/news/post/119027.html">如何将WPS行中的文本调整到行中
- 系统 字体问题(win10系统怎么设置密码)" href="https://www.huoban.com/news/post/62643.html">WIN10系统 字体问题(win10系统怎么设置密码)
- 格式的应用(应用文标题的格式)" href="https://www.huoban.com/news/post/63002.html">标题格式的应用(应用文标题的格式)


热评文章
零代码开发是什么?2022低代码平台排行榜">零代码开发是什么?2022低代码平台排行榜
进销存库存管理系统(智慧进销存)">智能进销存库存管理系统(智慧进销存)
在线文档哪家强?8款在线文档编辑软件推荐">在线文档哪家强?8款在线文档编辑软件推荐
WPS2016怎么绘制简单的价格表?
定制订单管理系统(为特定需求定制的订单管理系统)
系统的功能有哪些?餐饮服务系统的构成及工作程序">连锁餐饮管理系统的功能有哪些?餐饮服务系统的构成及工