

干货|深入理解神经网络(深度神经网络通俗理解)
本文将介绍用于解决实际问题的深度学习架构的不同模块。前一章使用PyTorch的低级操作构建了如网络架构、损失函数和优化器这些模块。本章将介绍用于解决真实问题的神经网络的一些重要组件,以及PyTorch如何通过提供大量高级函数来抽象出复杂度。本章还将介绍用于解决真实问题的算法,如回归、二分类、多类别分类等。
本文将讨论如下主题:
详解神经网络的不同构成组件;
探究PyTorch中用于构建深度学习架构的高级功能;
应用深度学习解决实际的图像分类问题。
1 详解神经网络的组成部分
上一章已经介绍了训练深度学习算法需要的几个步骤。
1.构建数据管道。
2.构建网络架构。
3.使用损失函数评估架构。
4.使用优化算法优化网络架构的权重。
上一章中的网络由使用PyTorch数值运算构建的简单线性模型组成。尽管使用数值运算为玩具性质的问题搭建神经架构很简单,但当需要构建解决不同领域的复杂问题时,如计算机视觉和自然语言处理,构建一个架构就迅速变得复杂起来。大多数深度学习框架,如PyTorch、TensorFlow和Apache MXNet,都提供了抽象出很多复杂度的高级功能。这些深度学习框架的高级功能称为层(layer)。它们接收输入数据,进行如同在前面一章看到的各种变换,并输出数据。解决真实问题的深度学习架构通常由1~150个层组成,有时甚至更多。抽象出低层的运算并训练深度学习算法的过程如图3.1所示。
图3.1
1.1 层——神经网络的基本组成
在本章的剩余部分,我们会见到各种不同类型的层。首先,先了解其中最重要的一种层:线性层,它就是我们前面讲过的网络层结构。线性层应用了线性变换:
{-:-}Y
=Wx
+b
线性层之所以强大,是因为前一章所讲的功能都可以写成单一的代码行,如下所示。
from torch.nn import Linear
myLayer = Linear(in_features=10,out_features=5,bias=True)
上述代码中的myLayer层,接受大小为10的张量作为输入,并在应用线性变换后输出一个大小为5的张量。下面是一个简单例子的实现:
可以使用属性weights和bias访问层的可训练参数:
线性层在不同的框架中使用的名称有所不同,有的称为dense层,有的称为全连接层(fully connected layer)。用于解决真实问题的深度学习架构通常包含不止一个层。在PyTorch中,可以用多种方式实现。
一个简单的方法是把一层的输出传入给另一层:
inp = Variable(torch.randn(1,10))
myLayer = Linear(in_features=10,out_features=5,bias=True)
myLayer(inp)
每一层都有自己的学习参数,在多个层的架构中,每层都学习出它本层一定的模式,其后的层将基于前一层学习出的模式构建。把线性层简单堆叠在一起是有问题的,因为它们不能学习到简单线性表示以外的新东西。我们通过一个简单的例子看一下,为什么把线性层堆叠在一起的做法并不合理。
假设有具有如下权重的两个线性层:
以上包含两个不同层的架构可以简单表示为带有另一不同层的单层。因此,只是堆叠多个线性层并不能帮助我们的算法学习任何新东西。有时,这可能不太容易理解,我们可以用下面的数学公式对架构进行可视化:
{-:-}Y
= 2(3X
1
) -2 Linear layers
{-:-}Y
= 6(X
1
) -1 Linear layers
为解决这一问题,相较于只是专注于线性关系,我们可以使用不同的非线性函数,帮助学习不同的关系。
深度学习中有很多不同的非线性函数。PyTorch以层的形式提供了这些非线性功能,因为可以采用线性层中相同的方式使用它们。
一些流行的非线性函数如下所示:
sigmoid
tanh
ReLU
Leaky ReLU
1.2 非线性激活函数
非线性激活函数是获取输入,并对其应用数学变换从而生成输出的函数。我们在实战中可能遇到数个非线性操作。下面会讲解其中几个常用的非线性激活函数。
sigmoid激活函数的数学定义很简单,如下:
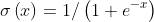
简单来说,sigmoid函数以实数作为输入,并以一个0到1之间的数值作为输出。对于一个极大的负值,它返回的值接近于0,而对于一个极大的正值,它返回的值接近于1。图3.2所示为sigmoid函数不同的输出。
图3.2
sigmoid函数曾一度被不同的架构使用,但由于存在一个主要弊端,因此最近已经不太常用了。当sigmoid函数的输出值接近于0或1时,sigmoid函数前一层的梯度接近于0,由于前一层的学习参数的梯度接近于0,使得权重不能经常调整,从而产生了无效神经元。
非线性函数tanh将实数值输出为-1到1之间的值。当tanh的输出极值接近-1和1时,也面临梯度饱和的问题。不过,因为tanh的输出是以0为中心的,所以比sigmoid更受偏爱,如图3.3所示。
图3.3
近年来ReLU变得很受欢迎,我们几乎可以在任意的现代架构中找到ReLU或其某一变体的身影。它的数学公式很简单:
{-:-}f(x)=max(0,x)
简单来说,ReLU把所有负值取作0,正值保持不变。可以对ReLU函数进行可视化,如图3.4所示。
图3.4
使用ReLU函数的一些好处和弊端如下。
有助于优化器更快地找到正确的权重集合。从技术上讲,它使随机梯度下降收敛得更快。
计算成本低,因为只是判断了阈值,并未计算任何类似于sigmoid或tangent函数计算的内容。
ReLU有一个缺点,即当一个很大的梯度进行反向传播时,流经的神经元经常会变得无效,这些神经元称为无效神经元,可以通过谨慎选择学习率来控制。我们将在第4章中讨论调整学习率的不同方式时,了解如何选择学习率。
Leaky ReLU尝试解决一个问题死角,它不再将饱和度置为0,而是设为一个非常小的数值,如0.001。对某些用例,这一激活函数提供了相较于其他激活函数更优异的性能,但它不是连续的。
1.3 PyTorch中的非线性激活函数
PyTorch已为我们实现了大多数常用的非线性激活函数,我们可以像使用任何其他的层那样使用它们。让我们快速看一个在PyTorch中使用ReLU激活函数的例子:
在上面这个例子中,输入是包含两个正值、两个负值的张量,对其调用ReLU函数,负值将取为0,正值则保持不变。
现在我们已经了解了构建神经网络架构的大部分细节,我们来构建一个可用于解决真实问题的深度学习架构。上一章中,我们使用了简单的方法,因而可以只关注深度学习算法如何工作。后面将不再使用这种方式构建架构,而是使用PyTorch中正常该用的方式构建。
PyTorch中所有网络都实现为类,创建PyTorch类的子类要调用nn.Module,并实现__init__和forward方法。在init方法中初始化层,这一点已在前一节讲过。在forward方法中,把输入数据传给init方法中初始化的层,并返回最终的输出。非线性函数经常被forward函数直接使用,init方法也会使用一些。下面的代码片段展示了深度学习架构是如何用PyTrorch实现的:
如果你是Python新手,上述代码可能会比较难懂,但它全部要做的就是继承一个父类,并实现父类中的两个方法。在Python中,我们通过将父类的名字作为参数传入来创建子类。init方法相当于Python中的构造器,super方法用于将子类的参数传给父类,我们的例子中父类就是nn.Module。
待解决的问题种类将基本决定我们将要使用的层,处理序列化数据问题的模型从线性层开始,一直到长短期记忆(LSTM)层。基于要解决的问题类别,最后一层是确定的。使用机器学习或深度学习算法解决的问题通常有三类,最后一层的情况通常如下。
对于回归问题,如预测T恤衫的销售价格,最后使用的是有一个输出的线性层,输出值为连续的。
将一张给定的图片归类为T恤衫或衬衫,用到的是sigmoid激活函数,因为它的输出值不是接近1就是接近0,这种问题通常称为二分类问题。
对于多类别分类问题,如必须把给定的图片归类为T恤、牛仔裤、衬衫或连衣裙,网络最后将使用softmax层。让我们抛开数学原理来直观理解softmax的作用。举例来说,它从前一线性层获取输入,并输出给定数量样例上的概率。在我们的例子中,将训练它预测每个图片类别的4种概率。记住,所有概率相加的总和必然为1。
一旦定义好了网络架构,还剩下最重要的两步。一步是评估网络执行特定的回归或分类任务时表现的优异程度,另一步是优化权重。
优化器(梯度下降)通常接受一个标量值,因而loss函数应生成一个标量值,并使其在训练期间最小化。某些用例,如预测道路上障碍物的位置并判断是否为行人,将需要两个或更多损失函数。即使在这样的场景下,我们也需要把损失组合成一个优化器可以最小化的标量。最后一章将详细讨论把多个损失值组合成一个标量的真实例子。
上一章中,我们定义了自己的loss函数。PyTorch提供了经常使用的loss函数的实现。我们看看回归和分类问题的loss函数。
回归问题经常使用的loss函数是均方误差(MSE)。它和前面一章实现的loss函数相同。可以使用PyTorch中实现的loss函数,如下所示:
对于分类问题,我们使用交叉熵损失函数。在介绍交叉熵的数学原理之前,先了解下交叉熵损失函数做的事情。它计算用于预测概率的分类网络的损失值,损失总和应为1,就像softmax层一样。当预测概率相对正确概率发散时,交叉熵损失增加。例如,如果我们的分类算法对图3.5为猫的预测概率值为0.1,而实际上这是只熊猫,那么交叉熵损失就会更高。如果预测的结果和真实标签相近,那么交叉熵损失就会更低。
图3.5
下面是用Python代码实现这种场景的例子。
为了在分类问题中使用交叉熵损失,我们真的不需要担心内部发生的事情——只要记住,预测差时损失值高,预测好时损失值低。PyTorch提供了loss函数的实现,可以按照如下方式使用。
PyTorch包含的其他一些loss函数如表3.1所示。
表3.1
计算出网络的损失值后,需要优化权重以减少损失,并改善算法准确率。简单起见,让我们看看作为黑盒的优化器,它们接受损失函数和所有的学习参数,并微量调整来改善网络性能。PyTorch提供了深度学习中经常用到的大多数优化器。如果大家想研究这些优化器内部的动作,了解其数学原理,强烈建议浏览以下博客:
http://colah.github.io/posts/2015-08-Backprop/
PyTorch提供的一些常用的优化器如下:
ADADELTA
Adagrad
Adam
SparseAdam
Adamax
ASGD
LBFGS
RMSProp
Rprop
SGD
第4章中将介绍更多算法细节,以及一些优势和折中方案考虑。让我们看看创建任意optimizer的一些重要步骤:
optimizer = optim.SGD(model.parameters(), lr = 0.01)
在上面的例子中,创建了SGD优化器,它把网络的所有学习参数作为第一个参数,另外一个参数是学习率,学习率决定了多大比例的变化调整可以作用于学习参数。第4章将深入学习率和动量(momentum)的更多细节,它们是优化器的重要参数。创建了优化器对象后,需要在循环中调用zero_grad()方法,以避免参数把上一次optimizer调用时创建的梯度累加到一起:
再一次调用loss函数的backward方法,计算梯度值(学习参数需要改变的量),然后调用optimizer.step()方法,用于真正改变调整学习参数。
现在已经讲述了帮助计算机识别图像所需要的大多数组件。我们来构建一个可以区分狗和猫的复杂深度学习模型,以将学到的内容用于实践。
1.4 使用深度学习进行图像分类
解决任何真实问题的重要一步是获取数据。Kaggle提供了大量不同数据科学问题的竞赛。我们将挑选一个2014年提出的问题,然后使用这个问题测试本章的深度学习算法,并在第5章中进行改进,我们将基于卷积神经网络(CNN)和一些可以使用的高级技术来改善图像识别模型的性能。大家可以从https://www.kaggle.com/c/dogs-vs-cats/data下载数据。数据集包含25,000张猫和狗的图片。在实现算法前,预处理数据,并对训练、验证和测试数据集进行划分是需要执行的重要步骤。数据下载完成后,可以看到对应数据文件夹包含了如图3.6所示的图片。
图3.6
当以图3.7所示的格式提供数据时,大多数框架能够更容易地读取图片并为它们设置标签的附注。也就是说每个类别应该有其所包含图片的独立文件夹。这里,所有猫的图片都应位于cat文件夹,所有狗的图片都应位于dog文件夹。
图3.7
Python可以很容易地将数据调整成需要的格式。请先快速浏览一下代码,然后,我们将讲述重要的部分。
上述代码所做的处理,就是获取所有图片文件,并挑选出2,000张用于创建验证数据集。它把图片划分到了cats和dogs这两个类别目录中。创建独立的验证集是通用的重要实践,因为在相同的用于训练的数据集上测试算法并不合理。为了创建validation数据集,我们创建了一个图片数量长度范围内的数字列表,并把图像无序排列。在创建validation数据集时,我们可使用无序排列的数据来挑选一组图像。让我们详细解释一下每段代码。
下面的代码用于创建文件:
files = glob(os.path.join(path,'*/*.jpg'))
glob方法返回特定路径的所有文件。当图片数量巨大时,也可以使用iglob,它返回一个迭代器,而不是将文件名载入到内存中。在我们的例子中,只有25,000个文件名,可以很容易加载到内存里。
可以使用下面的代码混合排列文件:
shuffle = np.random.permutation(no_of_images)
上述代码返回25,000个0~25,000范围内的无序排列的数字,可以把其作为选择图片子集的索引,用于创建validation数据集。
可以创建验证代码,如下所示:
上述代码创建了validation文件夹,并在train和valid目录里创建了对应的类别文件夹(cats和dogs)。
可以用下面的代码对索引进行无序排列:
在上面的代码中,我们使用无序排列后的索引随机抽出2000张不同的图片作为验证集。同样地,我们把训练数据用到的图片划分到train目录。
现在已经得到了需要格式的数据,我们来快速看一下如何把图片加载成PyTorch张量。
PyTorch的torchvision.datasets包提供了一个名为ImageFolder的工具类,当数据以前面提到的格式呈现时,它可以用于加载图片以及相应的标签。通常需要进行下面的预处理步骤。
1.把所有图片转换成同等大小。大多数深度学习架构都期望图片具有相同的尺寸。
2.用数据集的均值和标准差把数据集归一化。
3.把图片数据集转换成PyTorch张量。
PyTorch在transforms模块中提供了很多工具函数,从而简化了这些预处理步骤。例如,进行如下3种变换:
调整成256 ×256大小的图片;
转换成PyTorch张量;
归一化数据(第5章将探讨如何获得均值和标准差)。
下面的代码演示了如何使用ImageFolder类进行变换和加载图片:
train对象为数据集保留了所有的图片和相应的标签。它包含两个重要属性:一个给出了类别和相应数据集索引的映射;另一个给出了类别列表。
把加载到张量中的数据可视化往往是一个最佳实践。为了可视化张量,必须对张量再次变形并将值反归一化。下面的函数实现了这样的功能:
现在,可以把张量传入前面的imshow函数,将张量转换成图片:
imshow(train[50][0])
上述代码生成的输出如图3.8所示。
图3.8
在深度学习或机器学习中把图片进行批取样是一个通用实践,因为当今的图形处理器(GPU)和CPU都为批量图片的操作进行了优化。批尺寸根据我们使用的GPU种类而不同。每个GPU都有自己的内存,可能从2GB到12GB不等,有时商业GPU内存会更大。PyTorch提供了DataLoader类,它输入数据集将返回批图片。它抽象出了批处理的很多复杂度,如应用变换时的多worker的使用。下面的代码把前面的train和valid数据集转换到数据加载器(data loader)中:
DataLoader类提供了很多选项,其中最常使用的选项如下。
shuffle:为true时,每次调用数据加载器时都混合排列图片。
num_workers:负责并发。使用少于机器内核数量的worker是一个通用的实践。
对于大多的真实用例,特别是在计算机视觉中,我们很少构建自己的架构。可以使用已有的不同架构快速解决我们的真实问题。在我们的例子中,使用了流行的名为ResNet的深度学习算法,它在2015年赢得了不同竞赛的冠军,如与计算机视觉相关的ImageNet。为了更容易理解,我们假设算法是一些仔细连接在一起的不同的PyTorch层,并不关注算法的内部。在第5章学习卷积神经网络(CNN)时,我们将看到一些关键的ResNet算法的构造块。PyTorch通过torchvision.models模块提供的现成应用使得用户更容易使用这样的流行算法。因而,对于本例,我们快速看一下如何使用算法,然后再详解每行代码:
models.resnet18(pertrained = True)对象创建了算法的实例,实例是PyTorch层的集合。我们打印出model_ft,快速地看一看哪些东西构成了ResNet算法。算法的一小部分看起来如图3.9所示。这里没有包含整个算法,因为这很可能会占用几页内容。
图3.9
可以看出,ResNet架构是一个层的集合,包含的层为Conv2d、BatchNorm2d和 MaxPool2d,这些层以一种特有的方式组合在一起。所有这些算法都将接受一个名为pretrained的参数。当pretrained为True时,算法的权重已为特定的ImageNet分类问题微调好。ImageNet预测的类别有1000种,包括汽车、船、鱼、猫和狗等。训练该算法,使其预测1000种ImageNet类别,权重调整到某一点,让算法得到最高的准确率。我们为用例使用这些保存好并与模型共享的权重。与以随机权重开始的情况相比,算法以微调好的权重开始时会趋向于工作得更好。因而,我们的用例将从预训练好的权重开始。
ResNet算法不能直接使用,因为它是用来预测1,000种类别,而对于我们的用例,仅需预测猫和狗这两种类别。为此,我们拿到ResNet模型的最后一层——linear层,并把输出特征改成2,如下面的代码所示:
model_ft.fc = nn.Linear(num_ftrs, 2)
如果在基于GPU的机器上运行算法,需要在模型上调用cuda方法,让算法在GPU上运行。强烈建议在装备了GPU的机器上运行这些算法;有了GPU后,用很少的钱就可以扩展出一个云实例。下面代码片段的最后一行告知PyTorch在GPU上运行代码:
if is_cuda: model_ft = model_ft.cuda()
前一节中,我们已经创建了DataLoader实例和算法。现在训练模型。为此我们需要loss函数和optimizer:
在上述代码中,创建了基于CrossEntropyLoss的loss函数和基于SGD的优化器。StepLR函数帮助动态修改学习率。第4章将讨论用于调优学习率的不同策略。
下面的train_model函数获取模型输入,并通过多轮训练调优算法的权重降低损失:
上述函数的功能如下。
1.传入流经模型的图片并计算损失。
2.在训练阶段反向传播。在验证/测试阶段,不调整权重。
3.每轮训练中的损失值跨批次累加。
4.存储最优模型并打印验证准确率。
上面的模型在运行25轮后,验证准确率达到了87%。下面是前面的train_model函数在Dogs vs. Cats数据集上训练时生成的日志;为了节省篇幅,本书只包含了最后几轮的结果。
接下来的章节中,我们将学习可以以更快的方式训练更高准确率模型的高级技术。前面的模型在Titan X GPU上运行了30分钟的时间,后面将讲述有助于更快训练模型的不同技术。
2 小结
本章通过使用SGD优化器调整层权重,讲解了PyTorch中神经网络的全生命周期——从构成不同类型的层,到加入激活函数、计算交叉熵损失,再到优化网络性能(即最小化损失)。
本章还介绍了如何应用流行的ResNet架构解决二分类和多类别分类问题。
同时,我们尝试解决了真实的图像分类问题,把猫的图片归类为cat,把狗的图片归类为dog。这些知识可以用于对不同的实体进行分类,如辨别鱼的种类,识别狗的品种,划分植物种子,将***癌归类成Type1、Type2和Type3型等。
本文摘自《PyTorch深度学习》
译者:王海玲, 刘江峰
本书在不深入数学细节的条件下,给出了多个先进深度学习架构的直观解释,如ResNet、DenseNet、Inception和Seq2Seq等,也讲解了如何进行迁移学习,如何使用预计算特征加速迁移学习,以及如何使用词向量、预训练的词向量、LSTM和一维卷积进行文本分类。
阅读完本书后,读者将会成为一个熟练的深度学习人才,能够利用学习到的不同技术解决业务问题。
本文转载自异步社区
高性能计算 人工智能
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章
