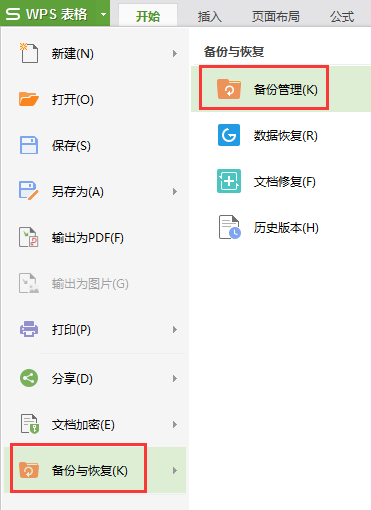
好烦 总是闪退,修复后是之前的文件!!!崩溃
602
2022-05-30

在日常开发工作中,你一定会经常遇到要根据指定字段进行排序的需求。
这时,你的SQL语句类似这样。
select id,phone,code from evt_sms where phone like '13020%' order by id desc limit 10
1
这个SQL的逻辑是十分清晰明了,但其内部的执行原理你知多少。
接下来,本期文章将带你打开order by的大门一探究竟。
本期所有结论都基于MySQL8.0.26版本
文章目录
最新文章
一、常见的Extra几个信息
二、文件排序
三、文件排序很慢,还有其它办法吗
四、优化文件排序
五、总结
最新文章
字符串可以这样加索引,你知吗?《死磕MySQL系列 七》
无法复现的“慢”SQL《死磕MySQL系列 八》
什么?还在用delete删除数据《死磕MySQL系列 九》
MySQL统计总数就用count(*),别花里胡哨的《死磕MySQL系列 十》
文章总目录
一、常见的Extra几个信息
在MySQL中想看一条SQL的性能不仅仅看是否用上了索引,还要看Extra中的内容,以下内容来自官方文档,给你最准确的学习资料。
using index
根据索引树可直接检索列信息,无需额外的操作来读取实际的行。
索引列即为查询列,也为条件列。
using index condition
下面这条语句name为普通索引,age无索引。
select * from table where name = ? and age = ?
索引下推是在MySQL5.6及以后的版本出现的。
之前的查询过程是,先根据name在存储引擎中获取数据,然后在根据age在server层进行过滤。
在有了索引下推之后,查询过程是根据name、age在存储引擎获取数据,返回对应的数据,不再到server层进行过滤。
当你使用Explain分析SQL语句时,如果出现了using index condition那就是使用了索引下推,索引下推是在组合索引的情况出现几率最大的。
using index for group_by
只查索引列,对索引列使用了group by
explain select phone from evt_sms where phone = "13054125874" group by phone;
1
using where
查询的列被索引覆盖,并且where筛选条件是索引列之一,但不是索引的前导列,Extra中为Using where; Using index,
意味着无法直接通过索引查找来查询到符合条件的数据
查询的列被索引覆盖,并且where筛选条件是索引列前导列的一个范围,同样意味着无法直接通过索引查找查询到符合条件的数据
zero limit
这个估计很少有小伙伴知道,就是你的SQL语句查询数量为limit 0
using temporary
使用了临时表,一般在使用group by、order by时会遇到。

这个也是本文即将要聊的话题。
using filesort
一般在使用group by、order by时会遇到,排序过程在内存中完成
Backward index scan
对索引列使用了降序操作
这里只列举了最常见的几个信息,MySQL官方文档中对Extra的解析大概有37个,感兴趣的可以去看看,后期咔咔也会逐步完善这块内容。
二、文件排序
由于是在一些统计、排序的业务中会经常见到Extra中出现using filesort的信息。
在MySQL8.0.26版本中对一个没有索引的列进行排序在Extra中显示using filesort。在低版本中需要你进行试验在什么情况下会出现。
在Extra中显示的using filesort表示的就是排序,MySQL会给每个线程分配一块内存用于排序,也被称之为sort_buffer。这期文章和下期文章会牵扯到很多名词,记得自己整理一下哈!
再看这条语句
那么这条SQL执行的具体流程是什么呢?
1、初始化sort_buffer,放入字段phone、code字段
2、在phone的索引树找到主键值
3、根据主键值到主键索引树中检索处phone、code对应字段的值,再存储sort_buffer中
4、继续从phone取下一个主键值
5、重复第三、第四,直到不满足phone = 条件为止
6、在sort_buffer中的数据按照字段phone做快排
7、按照快排的结果取出前10行返回改客户端即可
问题:所有的排序都是在内存中进行的?
当然不是,任何内存都不是无限制的,是否在内存中排序取决于MySQL参数sort_buffer_sort。
在MySQL8.0.26版本中这个值大小默认为256kb。
当需要排序的数据量大于256kb的阀值时,则会利用临时文件进行辅助排序,也就是常说的归并排序算法实现。
sort_buffer_size跟需要临时文件的个数成正比,如果sort_buffer_size越小则临时文件的数量就越多。
如何查看一个排序是否使用了临时文件,这个答案就交给大家来实现,版本不一致会导致很多结果都不同。
问题:你知道归并排序是如何实现的吗?
现在你知道了如果排序的数据大于sort_buffer_size会使用临时文件排序,这种排序使用的就是归并排序的思想,接下来让我们看看具体的流程是怎么样的。
1、把需要排序的数据分割,分割成每块数据都可以存放到sort_buufer中
2、对每块数据在sort_buufer中进行排序,排序好后,写入某个临时文件
3、当所有的数据都写入临时文件后,这时对于每个临时文件内部来说是有序的,但对于所有临时文件是无序的,所以还需要合并数据
4、假设现在存在tmp1和tmp2两个临时文件,这时分别从tmp1、tmp2读入部分数据到内存
5、假设从tmp1和tmp2中分别读入[0-5]的数据,然后分别使用tmp1[0]、tmp2[0] 进行对比,一直到tmp1[5]、tmp2[5],这样两两比较就可以把tmp1、tmp2合并为一个文件。经过几轮下来所有分割的数据都会合并为一个有序的大文件
三、文件排序很慢,还有其它办法吗
通过上面的案例,如果排序的数据量非常大则会超过sort_buffer_size的最大值,就只能使用文件排序,文件排序涉及了多次的文件合并是非常消耗性能的。
在上文你有没有发现一个细节,SQL中只需要排序code字段,但把phone字段也加到了sort_buufer中了。
这样单行的数据大小无形中就增大了,这样内存中能够存放的行数就减少了,需要分割成多个临时文件,排序性能会很差,那么有没有其它方案可以解决这种问题呢?
答案是肯定有的,就是接下来要聊的rowid排序。
先看一个参数max_length_for_sort_data
默认max_length_for_sort_data的大小为4096字节,假设现在要排序的数据非常多,我们可以修改这个参数让其使用rowid的算法。
MySQL中专门控制用户排序的行数据长度的参数,如果单行的数据长度超过了这个值,则MySQL会自动更换为rowid算法。
rowid排序的思想就是把不需要的数据不放到sort_buufer中,让sort_buffer中只存放需要排序的字段。
问题:如果你是设计者,你会存放那些字段
假设现在存放只需要排序的字段,排序很快完成了,拿到排序后的数据结果你应该怎么办呢?你已经无从下手了。
因此,你可以把主键ID的值也存放到sort_buufer中,当排序完成后通过ID回表即可得到排序后的数据。
执行流程
试想一下,这个执行流程其实跟文件排序的流程大差不差。
只是存放到sort_buufer中的字段变为需要排序的字段加上主键字段。
接着在sort_buufer中按照排序字段进行排序
最后再遍历排序结果,取需要的行数,并使用id进行回表一次,查出你需要的列即可。
注意点
这不是说使用了rowid的排序算法后就不使用临时文件排序了,不是这样的。
使用rowid只是存放到sort_buffer中的数据多个,若需要排序的数据很多还是需要使用临时文件的。
四、优化文件排序
如果MySQL发现sort_buufer内存太小,会影响排序效率,才会采用rowid排序算法,使用rowid算法的好处就是sort_buffer中可以一次排序更多的行,缺点就是需要回表。
在MySQL中如果内存够用,就多利用内存,尽量减少磁盘访问。所有rowid的算法不会被优先选择,因为回表会造成过的磁盘读。
不是所有的order by语句,都需要排序操作的,上面分析的两种排序算法的由来都是因为原来的数据都是无序的。
问题:什么是有序的?
看过了索引那一期文章后,你现在应该知道以下两点。
索引本身具有顺序性,在进行范围查询时,获取的数据已经排好了序,从而避免服务器再次排序和建立临时表的问题。
索引的底层实现本身具有顺序性,通过磁盘预读使得在磁盘上对数据的访问大致呈顺序的寻址,也就是将随机的I/O变为顺序I/O。
问题:如何防止进行排序
现在你应该知道答案了,就是给需要排序的列创建联合索引。
现在给phone、code建立一个联合索引,对应的SQL语句如下
alter table evt_sms add index idx_phone_code (phone,code);
1
那么执行同样的语句就不会使用排序操作了,接下来看一下执行流程
执行流程
1、从索引(phone,code)找到满足phone='123456’的记录,取出phone、code的值,作为结果集的一部分直接返回
3、从索引(phone、code)取下一个记录,同样取出phone、code的值,作为结果集的一部分直接返回
4、重复步骤2直到查出1000行数据,或者不满足查询条件为止
五、总结
order by没有用到索引时,执行计划中会出现using filesort
using filesort根据参数sort_buffer_size的值来决定使用需要使用临时文件
max_length_for_sort_data参数决定是否使用rowid算法,若放入sort_buffer的每行数据大于设置的值就会使用rowid算法
现在你应该知道了rowid排序只是把需要排序的字段和主键ID放入sort_buffer中,而文件排序则是把查询的所有字段全部放入sort_buffer中。
还有rowid会多造成一次回表操作,这个你也要知道。
最后提到了优化order by语句,这里提到了建立覆盖索引,利用索引的有序性直接返回结果不用进行排序。
这里并不是提倡大家在实际生产环境中盲目建立,而是根据具体业务情况,如果数据非常的小在内存排序是非常快的。并且覆盖索引会占用更多的存储空间和维护开销。
坚持学习、坚持写作、坚持分享是咔咔从业以来所秉持的信念。愿文章在偌大的互联网上能给你带来一点帮助,我是咔咔,下期见。
MySQL SQL
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。