
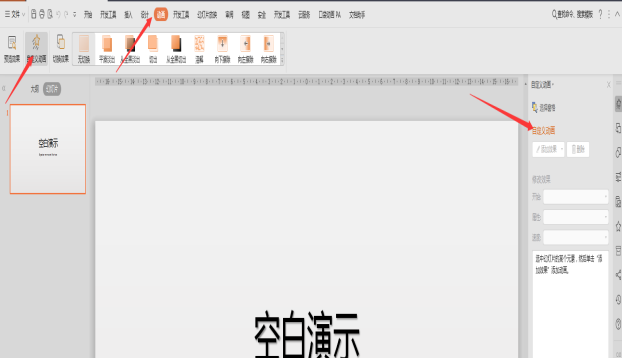
我的wps2019没有自定义动画窗格,怎么点都没有反应,右侧出不来。重装没用,请问怎么解决?
952
2022-05-30

Pandas是Python第三方库,提供高性能易用数据类型和分析工具
官网文档:http://pandas.pydata.org/pandas-docs/stable/10min.html
引入:
import pandas as pd
1
Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
两个数据类型:Series, DataFrame
基于上述数据类型的各类操作
基本操作
运算操作
特征类操作
关联类操作
Series类型
Series类型由一组数据及与之相关的数据索引组成
自动索引
自定义索引
Series是一维带“标签”数组
结构:data_a index_0
Series基本操作类似ndarray和字典,根据索引对齐
Series类型创建:
Python列表,index与列表元素个数一致
标量值,index表达Series类型的尺寸
Python字典,键值对中的“键”是索引,index从字典中进行选择操作
ndarray,索引和数据都可以通过ndarray类型创建
其他函数,range()函数等
Series类型基本操作
Series类型包括index和values两部分
.index 获得索引
.values 获得数据
Series类型的操作类似ndarray类型
索引方法相同,采用[]
NumPy中运算和操作可用于Series类型
可以通过自定义索引的列表进行切片
可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
Series类型的操作类似Python字典类型:
通过自定义索引访问
保留字in操作
使用.get()方法
Series类型对齐操作
Series+ Series
Series类型在运算中会自动对齐不同索引的数据
Series类型name属性
Series对象和索引都可以有一个名字,存储在属性.name中
Series类型的修改
对获取的值进行赋值
代码示例
# -*- coding: utf-8 -*- # @File : series_demo.py # @Date : 2018-05-19 import pandas as pd # 创建Series对象 d = pd.Series(range(5)) print(d) """ 0 0 1 1 2 2 3 3 4 4 dtype: int64 """ # 计算前N项和 print(d.cumsum()) """ 0 0 1 1 2 3 3 6 4 10 dtype: int64 """ # 自动索引 d = pd.Series([1, 2, 3, 4, 5]) print(d) """ 0 1 1 2 2 3 3 4 4 5 dtype: int64 """ # 自定义索引 d = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"]) print(d) """ a 1 b 2 c 3 d 4 e 5 dtype: int64 """ # 从标量值创建, 不能省略index s = pd.Series(20, index=["a", "b", "c"]) print(s) """ a 20 b 20 c 20 dtype: int64 """ # 从字典类型创建 s = pd.Series({"a": 1, "b": 2, "c": 3}) print(s) """ a 1 b 2 c 3 dtype: int64 """ # index从字典中进行选择操作 s = pd.Series({"a": 1, "b": 2, "c": 3}, index=["c", "a", "b", "d"]) print(s) """ c 3.0 a 1.0 b 2.0 d NaN dtype: float64 """ # 从ndarray类型创建 import numpy as np s = pd.Series(np.arange(5)) print(s) """ 0 0 1 1 2 2 3 3 4 4 dtype: int32 """ # 指定索引 s = pd.Series(np.arange(5), index=np.arange(9, 4, -1)) print(s) """ 9 0 8 1 7 2 6 3 5 4 dtype: int32 """ # Series基本操作 s = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"]) # 获得索引 print(s.index) # Index(['a', 'b', 'c', 'd', 'e'], dtype='object') # 获得值 print(s.values) # [1 2 3 4 5] # 自动索引和自定义索引并存 但不能混 print(s[0]) # 1 print(s["a"]) # 1 # 切片操作 print(s[["a", "b"]]) """ a 1 b 2 dtype: int64 """ # 类似ndarray类型 print(s[:3]) """ a 1 b 2 c 3 dtype: int64 """ print(s[s>s.median()]) """ d 4 e 5 dtype: int64 """ print(np.exp(s)) """ a 2.718282 b 7.389056 c 20.085537 d 54.598150 e 148.413159 dtype: float64 """ # 类似Python字典类型 print("b" in s) # True print(s.get("g", 100)) # 100 # Series类型对齐操作 a = pd.Series([1, 2, 3], index=["a", "b", "c"]) b = pd.Series([5, 6, 7, 8], index=["a", "b", "d", "e"]) print(a+b) """ a 6.0 b 8.0 c NaN d NaN e NaN dtype: float64 """ # Series类型name属性 s = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"]) s.name="Series" s.index.name = "索引" print(s) """ 索引 a 1 b 2 c 3 d 4 e 5 Name: Series, dtype: int64 """ # Series修改 s = pd.Series([1, 2, 3, 4, 5], index=["a", "b", "c", "d", "e"]) s[0] = 666 print(s) """ 0 666 1 2 2 3 3 4 4 5 dtype: int64 """ s["a", "b"] = 20 print(s) """ a 20 b 20 c 3 d 4 e 5 dtype: int64 """ # Series删除元素 s = pd.Series([1, 2, 3, 4, 5, 6], index=["a", "b", "c", "d", "e", "f"]) print(s) """ a 1 b 2 c 3 d 4 e 5 f 6 dtype: int64 """ s1 = s.drop(["a", "b"]) print(s1) """ c 3 d 4 e 5 f 6 dtype: int64 """
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41

42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
Python 数据挖掘
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。



