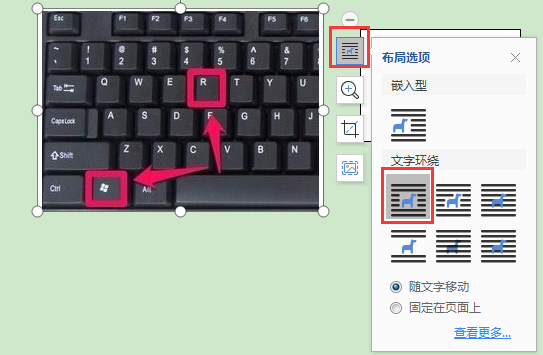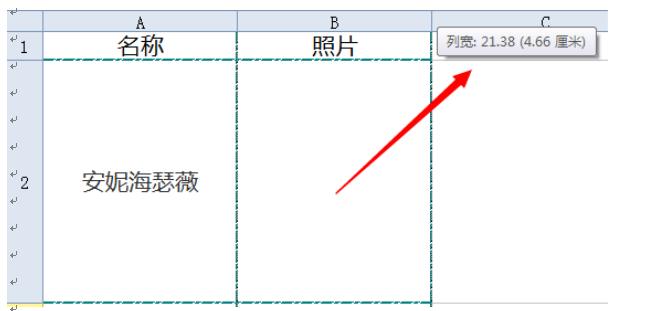
在表格中插入多张图片,但是图片都很大,怎么样操作能使插入的图片自动适应每一个单元格的大小,从而不用每
887
2022-05-30

1. 前言
平时工作中编写开发技术文档,或者学生在编写论文时,经常会上网搜索一些参考文献、文档。
比如: 上网搜索相似的内容参考一下或者引用别人的一段文字,有时候看到一篇较好的内容想要保存等等。
这个过程中会发现,很多网站的提供的页面都是不能复制粘贴的,或者直接是图片形式提供,为了方便能获取这些文字,当前就利用华为云提供的 通用文字识别接口,识别图片里的文本内容,方便复制文字。这个功能QQ上也集成了,使用很方便,这里利用华为云的接口实现一个与QQ类似的功能,截图之后识别图片里包含的文本内容。
这个文字识别接口里不仅仅有通用文字识别功能,还支持很多其他功能:比如身份证、驾驶证、保险单、手写文本、火车票,行驶证…等等功能。还支持用户自定义识别模板,指定需要识别的关键字段,实现用户特定格式图片的自动识别和结构化提取。
2. 文本识别接口使用介绍
2.1 开通服务
地址: https://console.huaweicloud.com/ocr/?region=cn-north-4#/ocr/overview

这个文字识别服务是按调用次数计费的,每个用户每月有1000次的免费调用次数,开通服务后就可以使用。
2.2 接口地址
官网帮助文档: https://support.huaweicloud.com/api-ocr/ocr_03_0042.html
POST https://{endpoint}/v2/{project_id}/ocr/general-text 示例: https://ocr.cn-north-4.myhuaweicloud.com/v2/0e5957be8a00f53c2fa7c0045e4d8fbf/ocr/general-text 请求头: { "X-Auth-Token": "******", "Content-Type": "application/json;charset=UTF-8" } 请求体: { "image": ----这是图片的bas64编码 } 响应结果: { "result": { "words_block_count": 13, "words_block_list": [ { "words": "撤,还是不撤?", "location": [ [ 43, 39 ], [ 161, 39 ], [ 161, 60 ], [ 43, 60 ] ] }, { "words": "让我更骄傲的是公司在大灾面前的表现。", "location": [ [ 72, 95 ], [ 332, 95 ], [ 332, 113 ], [ 72, 113 ] ] }, { "words": "2011年3月11日14时46分,日本东北部海域发生里氏9.0级", "location": [ [ 71, 122 ], [ 482, 122 ], [ 482, 142 ], [ 71, 142 ] ] }, { "words": "地震并引发海啸。那一刻,我们正在距离东京100公里的热海开会,", "location": [ [ 41, 149 ], [ 481, 149 ], [ 481, 171 ], [ 41, 171 ] ] }, { "words": "感觉“咚”", "location": [ [ 42, 180 ], [ 114, 180 ], [ 114, 199 ], [ 42, 199 ] ] }, { "words": "地被震了一下。面对地震,", "location": [ [ 115, 178 ], [ 296, 178 ], [ 296, 199 ], [ 115, 199 ] ] }, { "words": "大家都很镇定,", "location": [ [ 300, 179 ], [ 400, 179 ], [ 400, 197 ], [ 300, 197 ] ] }, { "words": "直到看到电", "location": [ [ 405, 179 ], [ 483, 179 ], [ 483, 196 ], [ 405, 196 ] ] }, { "words": "视上触目惊心的画面:15时 25 分,海啸到达陆前高田市海岸;15时", "location": [ [ 41, 206 ], [ 485, 206 ], [ 485, 228 ], [ 41, 228 ] ] }, { "words": "26分,海啸到达陆前高田市中心;15时43分,陆前高田市依稀只能", "location": [ [ 40, 234 ], [ 486, 234 ], [ 486, 258 ], [ 40, 258 ] ] }, { "words": "看到四层高的市府大楼的屋顶,一瞬间,城镇就变成了汪洋……对", "location": [ [ 40, 262 ], [ 487, 262 ], [ 487, 287 ], [ 40, 287 ] ] }, { "words": "我来说,地震跟家常便饭一样,可眼前的灾难比以往任何一次都要", "location": [ [ 40, 292 ], [ 487, 292 ], [ 487, 317 ], [ 40, 317 ] ] }, { "words": "惨烈,完全超出了我的预期。", "location": [ [ 41, 326 ], [ 231, 326 ], [ 231, 345 ], [ 41, 345 ] ] } ], "direction": -1 } }
2.3 在线调试接口
地址: https://apiexplorer.developer.huaweicloud.com/apiexplorer/debug?product=OCR&api=RecognizeGeneralText
使用调试接口想体验识别效果,图片的数据支持base64编码、http网络图片地址传入,测试非常方便。
关于获取图片base64编码的方式,在文档里也有介绍,直接通过浏览器获取。
3. 实现代码
代码采用QT编写的,请求API接口实现调用。其他语言方法是一样的。
3.1 实现效果
3.2 核心代码
//解析反馈结果 void Widget::replyFinished(QNetworkReply *reply) { QString displayInfo=""; int statusCode = reply->attribute(QNetworkRequest::HttpStatusCodeAttribute).toInt(); //读取所有数据 QByteArray replyData = reply->readAll(); qDebug()<<"状态码:"<
AI
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。