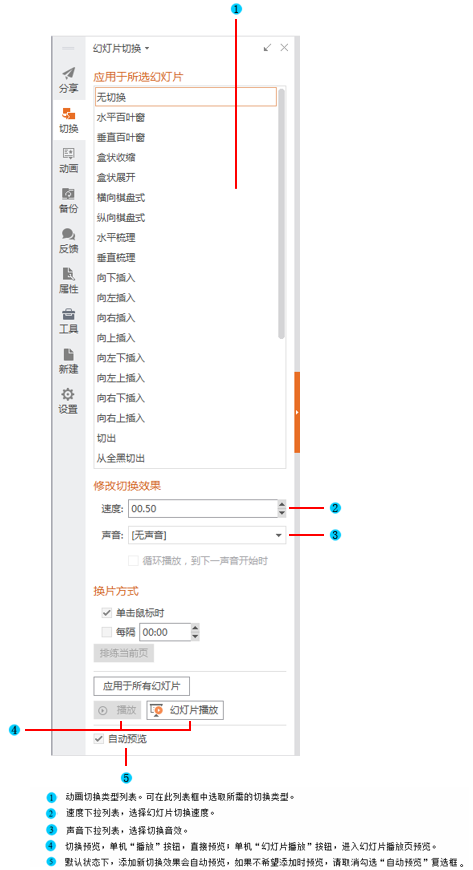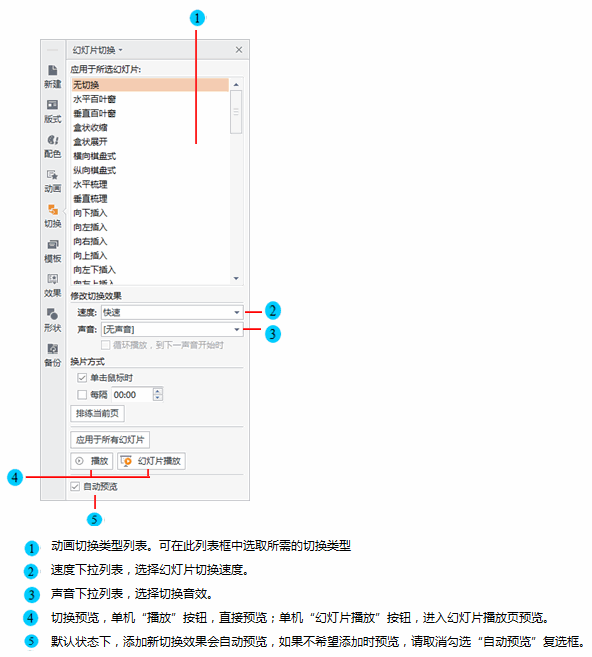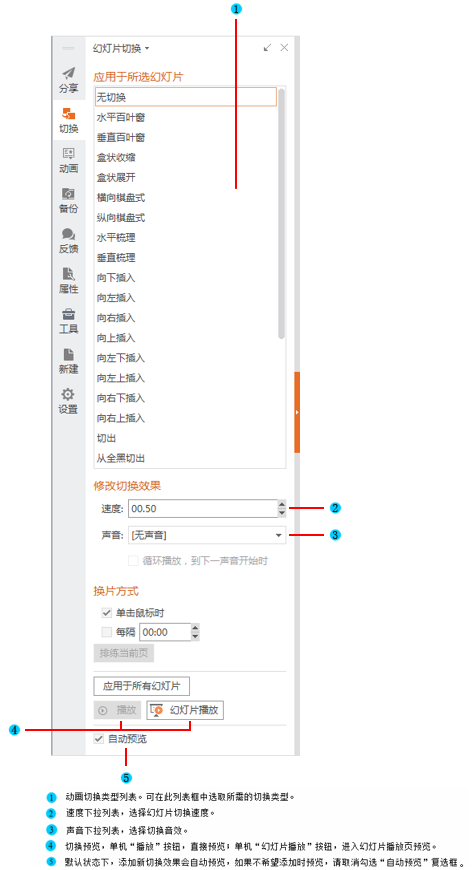
如何让一张幻灯片中的内容一个一个出来(制作幻灯片时,怎样让答案一个一个出来)
665
2022-05-28

文章目录
linux应用开发:标准IO库(下)
一、文件状态判断
1.1 feof() 函数
1.2 ferror() 函数
1.3 clearerr() 函数
二、格式化 I/O
2.1 格式化输出
2.2 格式化输入
三、I/O 缓冲
3.1 什么是文件 I/O 的内核缓冲
3.2 刷新文件 I/O 的内核缓冲区
3.3 内核缓冲标志
3.4 直接 I/O:绕过内核缓冲
3.5 标准 I/O 的 stdio 缓冲
四、文件描述符与 FILE 指针互转
Linux应用开发:标准IO库(下)
一、文件状态判断
我们在使用 fread() 读取数据时,如果发生了错误或者已经到了文件末尾(文件结束 end-of-file 置位)的情况,读取文件操作会停止,这时我们可以通过错误标志和判断文件末尾标志进行判断,定位问题出现在哪里,下面的函数就是判断这些标志的接口函数
1.1 feof() 函数
feof() 用于 测试参数文件的 end-of-file 标志,如果 end-of-file 标志被设置了,则调用 feof()函数将返回一个非零值,如果 end-of-file 标志没有被设置,则返回 0,函数原型如下:
#include
1
")
2
判断文件是否到末尾可以用如下判断方式:
if(feof(file)) { //指向文件已经到达文件末尾 }else { //指向文件未到达文件末尾 }
1
2
3
4
5
6
7
1.2 ferror() 函数
用于 测试文件的错误标志,如果错误标志被设置了,则调用 ferror()函数将返回一个非零值,如果错误标志没有被设置,则返回 0,函数原型如下:
#include
1
2
判断操作文件是否发生错误:
if (ferror(file)) { // 发生错误 } else { // 未发生错误 }
1
2
3
4
5
6
1.3 clearerr() 函数
clearerr() 用于清除 end-of-file 标志和错误标志,在调用 feof()或 ferror() 校验标志后,通常需要清除这些标志,避免下次校验时使用到的是上一次设置的值,函数原型:
#include
1
2
函数没有返回值,调用将总会成功
二、格式化 I/O
2.1 格式化输出
C 库函数提供了 5 个格式化输出函数,包括:printf()、fprintf()、dprintf()、sprintf()、snprintf(),函数定义如下
#include
1
2
3
4
5
6
2.1.1 printf() 函数
将程序中的字符串信息输出显示到终端
2.1.2 fprintf()函数
可将格式化数据写入到 由 FILE 指针指定的文件中,如将字符串“Hello World”写入到标准错误文件中:
fprintf(stderr, "Hello World!\n");
1
2.1.3 dprintf()函数
dprintf()可将格式化数据写入到由 文件描述符 fd 指定的文件中,将字符串“Hello World”写入到标准错误文件
dprintf(STDERR_FILENO, "Hello World!\n");
1
2.1.4 sprintf()函数
sprintf()函数将格式化数据存储在由 参数 buf 所指定的缓冲区中,譬如将字符串“Hello World”存放在缓冲区中
char buf[100]; sprintf(buf, "Hello World!\n");
1
2
sprintf()函数会在字符串尾端自动加上一个字符串终止字符’\0’
2.1.5 snprintf()函数
sprintf() 函数可能会发生缓冲区溢出的问题,存在安全隐患,为了解决这个问题,引入了 snprintf() 函数;在该函数中,使用参数 size 显式的指定缓冲区的大小,如果写入到缓冲区的字节数大于参数 size 指定的大小,超出的部分将会被丢弃!如果缓冲区空间足够大,snprintf()函数就会 返回写入到缓冲区的字符数,与 sprintf() 函数相同,也会在字符串末尾自动添加终止字符’\0’
2.2 格式化输入
C 库函数提供了 3 个格式化输入函数,包括:scanf()、fscanf()、sscanf(),其函数原型如下:
#include
1
2
3
4
2.2.1 scanf() 函数
scanf()函数将用户输入(标准输入)的数据进行格式化转换并进行存储,当程序中调用 scanf()的时候,终端会被阻塞,等待用户输入数据,例如从键盘输入数据存储到 a,b,c
int a, b, c; scanf("%d %d %d", &a, &b, &c);
1
2
函数发生错误则返回负值
2.2.2 fscanf() 函数
fscanf()函数 从指定文件中读取数据,作为格式转换的输入数据,文件通过 FILE 指针指定,如从标准输入文件中读取数据进行格式化转换
int a, b, c; fscanf(stdin, "%d %d %d", &a, &b, &c);
1
2
调用成功后,将返回成功匹配和分配的输入项的数量;如果较早匹配失败,则该数目可能小于所提供的数目,甚至为零。发生错误则返回负值
2.2.3 sscanf() 函数
sscanf()将从参数 str 所指向的字符串缓冲区中读取数据,作为格式转换的输入数据,如下从 str 中按照格式读数据存储到 buf 中:
char *str = "5454 hello"; char buf[10]; int a; sscanf(str, "%d %s", &a, buf);
1
2
3
4
三、I/O 缓冲
系统 I/O 调用(即文件 I/O,open、read、write 等)和标准 C 语言库 I/O 函数(即标准 I/O 函数)在操作磁盘文件时会对数据进行缓冲!
3.1 什么是文件 I/O 的内核缓冲
read() 和 write() 系统调用在进行文件读写操作的时候 不会直接访问磁盘设备,而是 在用户空间缓冲区和内核缓冲区(kernel buffer cache)之间复制数据,这个内核缓冲区就称为文件 I/O 的内核缓冲,因为磁盘操作通常是比较缓慢的,这一设计可以减少内核操作磁盘的次数,提高效率,至于内核什么时候将数据写入到磁盘设备中,具体什么时间点写入到磁盘,这个是不确定的,由内核根据相应的存储算法自动判断
文件 I/O 的内核缓冲区自然是越大越好,Linux 内核本身对内核缓冲区的大小没有固定上限。内核会分配尽可能多的内核空间来作为文件 I/O 的内核缓冲区,但也会受限于物理内存的总量,如果系统可用的物理内存越多,那自然对应的内核缓冲区也就越大,操作越大的文件也要依赖于更大空间的内核缓冲。
3.2 刷新文件 I/O 的内核缓冲区
Linux 中提供了一些系统调用可用于控制文件 I/O 内核缓冲,包括系统调用 sync()、syncfs()、fsync()以及 fdatasync() ,用于强制将文件 I/O 内核缓冲区中缓存的数据写入(刷新)到磁盘设备中或者其他的一些操作
3.2.1 fsync()函数
系统调用 fsync() 将参数 fd (文件描述符) 所指文件的内容数据和元数据写入磁盘,只有在对磁盘设备的写入操作完成之后,fsync()函数才会返回,函数原型
#include
1
2
元数据并不是文件内容本身的数据,而是一些用于记录文件属性相关的数据信息,譬如文件大小、时间戳、权限等等信息,这里统称为文件的元数据,这些信息也是存储在磁盘设备中的
3.2.2 fdatasync()函数
系统调用 fdatasync()与 fsync()类似,不同之处在于 fdatasync() 仅将参数 fd 所指文件的内容数据写入磁盘,并不包括文件的元数据;只有在对磁盘设备的写入操作完成之后,fdatasync()函数才会返回,函数原型:
#include
1
2
3.2.3 sync()函数
系统调用 sync()会将所有文件 I/O 内核缓冲区中的文件内容数据和元数据全部更新到磁盘设备中,该函数没有参数、也无返回值,函数原型
#include
1
2
频繁调用 fsync()、fdatasync()、sync() 会对性能的影响极大,使用需要注意
3.3 内核缓冲标志
调用 open() 函数时指定一些标志也可以影响到文件 I/O 内核缓冲,譬如 O_DSYNC 标志和 O_SYNC 标志
3.3.1 O_DSYNC 标志
调用 open()函数时,指定 O_DSYNC 标志,其效果类似于在每个 write() 调用之后调用 fdatasync() 函数进行数据同步,使用如下:
fd = open(filepath, O_WRONLY | O_DSYNC);
1
3.3.2 O_SYNC 标志
指定 O_SYNC 标志,其效果类似于在每个 write()调用之后调用 fsync() 函数进行数据同步,使用如下:
fd = open(filepath, O_WRONLY | O_SYNC);
1
3.4 直接 I/O:绕过内核缓冲
从 Linux 内核 2.4 版本开始,Linux 允许应用程序在执行文件 I/O 操作时绕过内核缓冲区,从用户空间直接将数据传递到文件或磁盘设备,把这种操作也称为直接 I/O(direct I/O)或裸 I/O(raw I/O)
要对某一文件或块设备执行直接 I/O,要在调用 open()函数打开文件时,指定 O_DIRECT 标志,该标志在 Linux 内核 2.4.10 版本开始生效,使用实例如下:
fd = open(filepath, O_WRONLY | O_DIRECT);
1
直接 I/O 使用的对齐限制
直接 I/O 涉及到对磁盘设备的直接访问,所以在执行直接 I/O 时,必须要遵守以下三个对齐限制:
应用程序中用于存放数据的缓冲区,其内存起始地址必须以块大小的整数倍进行对齐
写文件时,文件的位置偏移量必须是块大小的整数倍
写入到文件的数据大小必须是块大小的整数倍
不满足以上任何一个要求,调用 write() 进行写入时均为以错误返回 Invalid argument
直接 I/O 效率、性能比较低,绝大部分应用程序不会使用直接 I/O 方式对文件进行 I/O 操作,通常只在一些特殊的应用场合下才可能会使用,比如使用直接 I/O 方式来测试磁盘设备的读写速率,这种测试方式相比普通 I/O 方式就会更加准确
3.5 标准 I/O 的 stdio 缓冲
首先我们知道一点:
标准 I/O(fopen、fread、fwrite、fclose、fseek 等)是 C 语言标准库函数
文件 I/O(open、read、write、close、lseek 等)是系统调用
虽然标准 I/O 是在文件 I/O 基础上进行封装而实现,但在 效率、性能上标准 I/O 要优于文件 I/O,其 原因在于标准 I/O 实现维护了自己的缓冲区,我们把这个缓冲区称为 stdio 缓冲区
文件 I/O 内核缓冲,这是由内核维护的缓冲区,而标准 I/O 所维护的 stdio 缓冲是用户空间的缓冲区,下面介绍一些对 stdio 缓冲区进行操作的函数:
3.5.1 setbuf()
setvbuf() 库函数可以对文件的 stdio 缓冲区进行设置,譬如缓冲区的缓冲模式、缓冲区的大小、起始地址等。其函数原型如下:
#include
1
2
函数参数和返回值含义如下:
mode 取值
3.5.2 setbuffer()
setbuf()函数构建与 setvbuf()之上,函数原型
#include
1
2
相当于执行如下程序:
setvbuf(stream, buf, buf ? _IOFBF : _IONBF, BUFSIZ);
1
3.5.3 setvbuf()
setbuffer() 函数类似于 setbuf(),但允许调用者指定 buf 缓冲区的大小,函数原型:
#include
1
2
调用除了不返回函数结果,调用结果类似于调用下面的代码
setvbuf(stream, buf, buf ? _IOFBF : _IONBF, size);
1
3.5.4 fflush()
fflush() 来强制刷新 stdio 缓冲区,该函数会刷新指定文件的 stdio 输出缓冲区,其实就是通过 write() 函数将输出到 stdio 缓冲区中的数据写入到内核缓冲区,函数原型如下:
#include
1
2
参数 stream 指定需要进行强制刷新的文件,如果该参数设置为 NULL,则表示刷新所有的 stdio 缓冲区,调用成功返回 0,否则将返回-1,并设置 errno 以指示错误原因
调用 fclose() 关闭文件时会自动刷新文件的 stdio 缓冲区
文件 I/O 内核缓冲区和 stdio 缓冲区之间的联系与区别如下图:
应用程序调用标准 I/O 库函数将用户数据写入到 stdio 缓冲区中(stdio 缓冲区是由 stdio 库所维护的用户空间缓冲区),当满足条件时,stdio 库会调用文件 I/O(系统调用 I/O)将 stdio 缓冲区中缓存的数据写入到内核缓冲区中,内核缓冲区位于内核空间,最终由内核向磁盘设备发起读写操作,将内核缓冲区中的数据写入到磁盘(写入操作由具体算法控制)
应用程序可以调用相关系统调用对内核缓冲区进行控制,譬如调用 fsync()、fdatasync()或 sync()来刷新内核缓冲区
四、文件描述符与 FILE 指针互转
在同一个文件上执行 I/O 操作时,可以将文件 I/O(系统调用 I/O)与标准 I/O 混合使用,这个时候我们就需要将文件描述符和 FILE 指针对象之间进行转换,
库函数 fileno() 可以将标准 I/O 中使用的 FILE 指针转换为文件 I/O 中所使用的文件描述符,而 fdopen() 则进行着相反的操作,函数原型如下:
#include
1
2
3
fileno() 根据传入的 FILE 指针得到整数文件描述符,通过返回值得到文件描述符,如果转换错误将返回-1,且会设置 errno 来指示错误原因
fdopen() 给定一个文件描述符,得到该文件对应的 FILE 指针
Linux
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。